一、事务并发调度的问题
- 脏读:A事务读取B事务尚未提交的更改数据,并在这个数据基础上操作。如果B事务回滚,那么A事务读到的数据根本不是合法的,称为脏读。在oracle中,由于有version控制,不会出现脏读。
- 不可重复读:A事务读取了B事务已经提交的更改(或删除)数据。比如A事务第一次读取数据,然后B事务更改该数据并提交,A事务再次读取数据,两次读取的数据不一样。
- 幻读:A事务读取了B事务已经提交的新增数据。注意和不可重复读的区别,这里是新增,不可重复读是更改(或删除)。这两种情况对策是不一样的,对于不可重复读,只需要采取行级锁防止该记录数据被更改或删除,然而对于幻读必须加表级锁,防止在这个表中新增一条数据。
- 第一类丢失更新:A事务撤销时,把已提交的B事务的数据覆盖掉。
- 第二类丢失更新:A事务提交时,把已提交的B事务的数据覆盖掉。
三级封锁协议
- 一级封锁协议:事务T中如果对数据R有写操作,必须在这个事务中对R的第一次读操作前对它加X锁,直到事务结束才释放。事务结束包括正常结束(COMMIT)和非正常结束(ROLLBACK)。
- 二级封锁协议:一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,读完后方可释放S锁。
- 三级封锁协议 :一级封锁协议加上事务T在读取数据R之前必须先对其加S锁,直到事务结束才释放。
可见,三级锁操作一个比一个厉害(满足高级锁则一定满足低级锁)。但有个非常致命的地方,一级锁协议就要在第一次读加x锁,直到事务结束。几乎就要在整个事务加写锁了,效率非常低。三级封锁协议只是一个理论上的东西,实际数据库常用另一套方法来解决事务并发问题。
二、隔离性级别
mysql用意向锁(另一种机制)来解决事务并发问题,为了区别封锁协议,弄了一个新概念隔离性级别:包括Read Uncommitted、Read Committed、Repeatable Read、Serializable。mysql 一般默认Repeatable Read。
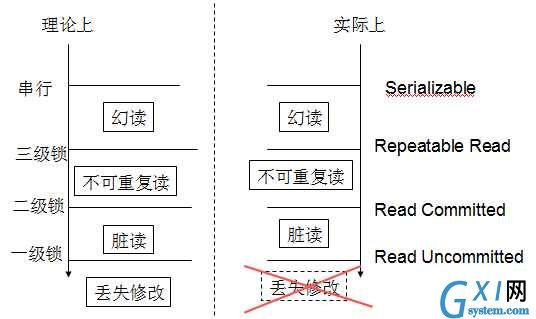
总结一下,repeatable read能解决脏读和不可重复读,但不能解决丢失修改。
三、mysql的行锁和表锁
下面对行锁和表锁进行一个简单的介绍。
- 表级锁:每次操作锁住整张表。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
- 行级锁:每次操作锁住一行数据。开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
1、MyISAM的锁
稍微提一下MyISAM,只说和InnoDB不同的。
a. MyISAM只有表锁,锁又分为读锁和写锁。
b. 没有事务,不用考虑并发问题
c. 由于锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了。
2、InnoDB的行锁和表锁
没有特定的语法。mysql的行锁是通过索引体现的。
如果where条件中只用到索引项,则加的是行锁;否则加的是表锁。比如说主键索引,唯一索引和聚簇索引等。如果sql的where是全表扫描的,想加行锁也爱莫能助。
行锁和表锁对我们编程的影响是要在where中尽量只用索引项,否则就会触发表锁。
3、加锁和解锁
在InnoDB中,select,insert,update,delete等语句执行时都会自动加解锁。select的锁一般执行完就释放了,修改操作的X锁会持有到事务结束,效率高很多。
mysql也给用户提供了加锁的机会,只要在sql后加LOCK IN SHARE MODE 或FOR UPDATE
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
排他锁(X):SELECT * FROM table_name WHERE ... FOR UPDATE
值得注意的是,自己加的锁没有释放锁的语句,所以锁会持有到事务结束。
四、解决丢失修改--乐观锁和悲观锁
加锁就是为了解决丢失修改。如果一个事务中只有一句sql,数据库是可以保证它是并发安全的。丢失修改的特征就是在一个事务中先读P数据,再写P数据。所谓丢失修改,一般是A事务有两个操作,后一个操作依赖于前一个操作,之后后一个操作覆盖了B事务的写操作。
如果一个事务先读后写同一份数据,就可能发生丢失修改,要做一些处理。下面对乐观锁和悲观锁进行一个简单的介绍。
悲观锁和乐观锁的概念:
悲观锁(Pessimistic Concurrency Control,PCC):假定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。
乐观锁(Optimistic Concurrency Control,OCC):假设不会发生并发冲突,只在提交操作时检查是否违反数据完整性。
乐观锁和悲观锁也不仅仅能用在数据库中,也能用在线程中。
悲观锁的缺陷是不论是页锁还是行锁,加锁的时间可能会很长,这样可能会长时间的限制其他用户的访问,也就是说悲观锁的并发访问性不好。
乐观锁不能解决脏读,加锁的时间要比悲观锁短(只是在执行sql时加了基本的锁保证隔离性级别),乐观锁可以用较大的锁粒度获得较好的并发访问性能。但是如果第二个用户恰好在第一个用户提交更改之前读取了该对象,那么当他完成了自己的更改进行提交时,数据库就会发现该对象已经变化了,这样,第二个用户不得不重新读取该对象并作出更改。
可见,乐观锁更适合解决冲突概率极小的情况;而悲观锁则适合解决并发竞争激烈的情况,尽量用行锁,缩小加锁粒度,以提高并发处理能力,即便加行锁的时间比加表锁的要长。
悲观锁的例子
这里仅仅提供一种解决丢失修改的悲观锁例子。丢失修改的特征就是在一个事务中先读P数据,再写P数据。而且一级锁协议能解决丢失修改,所以如果事务A 中写P,我们只要在A中第一次读P前加X锁。
乐观锁的例子
乐观锁检测并发冲突的常见的两种做法:
- 使用数据版本(Version)。在P数据上(通常每一行)加version字段(int),A事务在读数据P 时同时读出版本号,在修改数据前检测最新版本号是否等于先前取出的版本号,如果是,则修改,同时把版本号+1;否则要么回滚,要么重新执行事务。另外,数据P的所有修改操作都要把版本号+1。有一个非常重要的点,版本号是用来查看被读的变量有无变化,而不是针对被写的变量,作用是防止被依赖的变量有修改。
- 使用时间戳(TimeStamp)。做法类似于1中。
总结
乐观锁更适合并发竞争少的情况,最好隔那么3-5分钟才有一次冲突。当并发量为10时就能明显感觉乐观锁更慢;
上面只是一读一写。考虑如果一个事务中有3个写,如果每次写都是九死一生,事务提交比较难,这时就更要考虑是不是要用乐观锁了。
但是,当分布式数据库规模大到一定程度后,又另说了。基于悲观锁的分布式锁在集群大到一定程度后(从几百台扩展到几千台时),性能开销就打得无法接受。所以目前的趋势是大规模的分布式数据库更倾向于用乐观锁来达成external consistency。



























