day16 事务 - 数据库连接池 - 编写自己的jdbc框架
时间:2022-03-15 08:49
Author:相忠良
Email:
起始于:June 8, 2018
最后更新日期:June 11, 2018
声明:本笔记依据传智播客方立勋老师 Java Web 的授课视频内容记录而成,中间加入了自己的理解。本笔记目的是强化自己学习所用。若有疏漏或不当之处,请在评论区指出。谢谢。
涉及的图片,文档写完后,一次性更新。
1. 事务

发sql时,把多个sql放在Start transaction和commit之间即可。
试验准备:
create table account(
id int primary key auto_increment,
name varchar(40),
money float
)character set utf8 collate utf8_general_ci;
insert into account(name,money) values(‘aaa‘,1000);
insert into account(name,money) values(‘bbb‘,1000);
insert into account(name,money) values(‘ccc‘,1000);现在,a向b转账100元,操作如下:
start transaction;
update account set money=money-100 where name=‘aaa‘;关掉连接,重新登录数据库查看,aaa 账户的 money 还是 1000。
只有下面这样才行:
start transaction;
update account set money=money-100 where name=‘aaa‘;
update account set money=money+100 where name=‘bbb‘;
commit;执行到 commit,上面2条sql才算真正执行,而不是回滚,这就是事务(控制多条sql作为整体执行)。
rollback 可以手动回滚,而不是异常时,事务在数据库中自动回滚。
当Jdbc程序向数据库获得一个Connection对象时,默认情况下这个Connection对象会自动向数据库提交在它上面发送的SQL语句。若想关闭这种默认提交方式,让多条SQL在一个事务中执行,可使用下列语句:
JDBC控制事务语句:
Connection.setAutoCommit(false);相当于 start transactionConnection.rollback();rollbackConnection.commit();commit
程序中控制事务的例子如下:
public class Demo1 {
/**
a--->b 100
*/
public static void main(String[] args) throws SQLException {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try{
conn = JdbcUtils.getConnection();
conn.setAutoCommit(false); //start transaction;
String sql1 = "update account set money=money-100 where name=‘aaa‘";
String sql2 = "update account set money=money+100 where name=‘bbb‘";
st = conn.prepareStatement(sql1);
st.executeUpdate();
int x = 1/0; // <-- 产生异常
st = conn.prepareStatement(sql2);
st.executeUpdate();
conn.commit(); // commit
}finally{
JdbcUtils.release(conn, st, rs);
}
}
}1.1 事务回滚点
手动回滚,按下面例子,只想从第二条sql开始回滚,方法就是:
- 设置回滚点
Savepoint; - 手动设置 commit。
例子如下:
public class Demo2 {
public static void main(String[] args) throws SQLException {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
Savepoint sp = null; // 回滚点对象
try {
conn = JdbcUtils.getConnection();
conn.setAutoCommit(false); // start transaction;
String sql1 = "update account set money=money-100 where name=‘aaa‘";
String sql2 = "update account set money=money+100 where name=‘bbb‘";
String sql3 = "update account set money=money+100 where name=‘ccc‘";
st = conn.prepareStatement(sql1);
st.executeUpdate();
sp = conn.setSavepoint(); // <-- 2. 设置回滚点
st = conn.prepareStatement(sql2);
st.executeUpdate();
int x = 1 / 0; // <-- 1. 产生异常
st = conn.prepareStatement(sql3);
st.executeUpdate();
conn.commit(); // commit
} catch (Exception e) {
e.printStackTrace();
conn.rollback(sp); // <-- 3. 回滚
conn.commit(); // <-- 4. 手动回滚后,一定要记得提交事务
} finally {
JdbcUtils.release(conn, st, rs);
}
}
}1.2 事务四大特性 ACID
若一个数据库号称支持事务,那它必然支持 ACID;反过来说,若某数据库支持 ACID,那这个数据库也是支持事务的。
- 原子性(Atomicity) 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生;
- 一致性(Consistency) 事务前后数据的完整性必须保持一致;
- 隔离性(Isolation) 事务的隔离性是多个用户 并发访问 数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离;
- 持久性(Durability) 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
1.2.1 隔离性 - 脏读 - 不可重复读 - 虚读(幻读)
脏读:指一个事务读取了另外一个事务未提交的数据。(最危险)
故事:这是非常危险的,假设 A 向 B 转帐 100 元,对应 sql 语句如下所示:
update account set money=money+100 while name=‘b‘;update account set money=money-100 while name=‘a‘;
当第 1 条 sql 执行完,第 2 条还没执行(A 未提交时),如果此时 B 查询自己的帐户,就会发现自己多了 100 元钱。如果 A 等 B 走后再回滚,B 就会损失 100 元。
下面介绍的不可重复读和幻读,有些情况下是没问题的,但有时会有问题。
不可重复读:在一个事务内读取表中的某一行数据,多次读取结果不同。 也指读表中同一条数据,结果不同。
故事:中国人民银行生成开启生成报表这个事务,报送克强总理1000亿RMB,在报送近平主席前,生成报表这个事务未结束期间,有客户存了200亿RMB并该客户完成了他的事务,现在又生成近平主席的报表显示为1200亿。问题出现了:两位领导要打架的。困惑就是:哪次查询时是准确的呢? 这就是不可重复读所产生的问题。
虚读(幻读):是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致。 也指所读的表的记录数在变化。
故事:人口普查系统正生成报表,开启了一个事务。该系统在这个事务中需生成多个报表。可能发生这样的事:生成第一个报表,显示中国有10亿人,但生成第二个报表期间,有人往数据库中插入了数据,统计结果显示有11亿人。困惑来了:到底以哪个为准呢?这就是幻读产生的问题。
1.3 事务的隔离级别
根据上节介绍的,若无隔离性,数据库可能出现的三种问题,针对问题的解决,提出了事务隔离级别。隔离级别的提出,主要在解决问题的基础上,尽可能的不过多损失数据库性能。
数据库共定义了四种隔离级别:
- Serializable:可避免脏读、不可重复读、虚读情况的发生。(串行化)
- Repeatable read:可避免脏读、不可重复读情况的发生。(可重复读)
- Read committed:可避免脏读情况发生(读已提交)。
- Read uncommitted:最低级别,以上情况均无法保证。(读未提交)
事务隔离性的设置语句:
set transaction isolation level设置事务隔离级别select @@tx_isolation查询当前事务隔离级别
方立勋老师开启了2个mysql客户端,进行了模拟。模拟过程这里不表述了。
编程序时,获得的 connection:
- 若是 mysql 的链接,默认隔离级别是repeatable read,mysql完全支持上述4种隔离级别;
- 若是 oracle 的链接,默认隔离级别是 read committed,且oracle只支持Serializable和Read committed这两种隔离级别。
编程中,用JDBC设置隔离级别: conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
示例代码:
public class Demo3 {
public static void main(String[] args) throws SQLException, InterruptedException {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
Savepoint sp = null;
try{
conn = JdbcUtils.getConnection(); //mysql repeatable read
conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
conn.setAutoCommit(false); //start transaction;
String sql = "select * from account";
conn.prepareStatement(sql).executeQuery();
Thread.sleep(1000*20);
conn.commit();
}finally{
JdbcUtils_DBCP.release(conn, st, rs);
}
}
}2. 数据库连接池
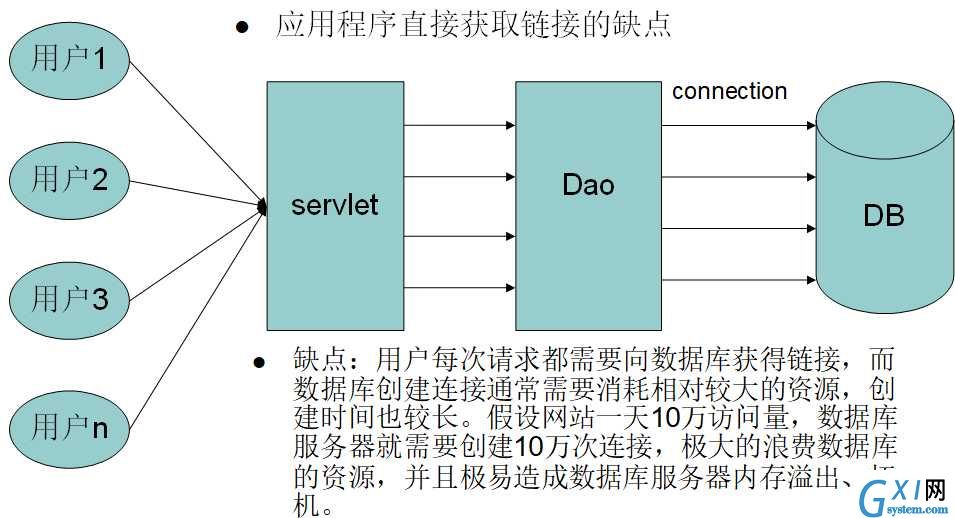
下图展示了无数据库连接池时的缺点:
下图是有连接池的情形:
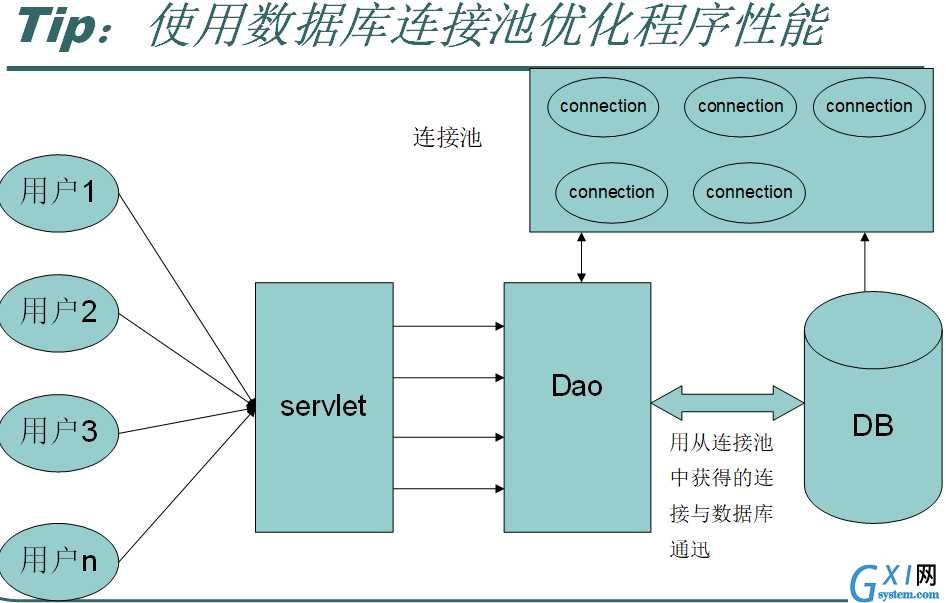
有连接池后,数据库就不必为每个用户创建连接,而仅仅在一开始生成一些连接(假如20个),并将这些连接放入连接池,其他用户只从池中拿连接,用完后还到池中。(这个故事主要考虑,数据库自己创建1个连接需消耗很多资源,10万用户申请,就创建10万次连接,数据库本身做本职工作就很繁忙,再去频繁地创建若此多的链接,数据库极有可能被累死!我们要做的是尽量减轻数据库服务器的负担。)
故事:
我们希望执行conn.close();时,连接还回连接池,但事实是conn是mysql提供的链接,执行close方法时,那个连接将还给mysql,而不是连接池。
当发现对象的方法不够我们用时,我们需增强那个方法。办法有:
- 写一个Connection子类,覆盖close方法,增强close方法;
- 用包装设计模式;
- 用动态代理。
通常子类的方式不可行,原因是很难将父类对象信息导入子类对象中,除非父类对象封装的信息极少。
包装设计模式步骤(我自己的经验,想象一下BufferedReader的用法,就是用构造函数接收被包装对象):
- 定义一个类,实现与被增强对象相同的接口;
- 在类中定义一个变量,记住被增强对象;
- 定义一个构造函数,接收被增强对象;
- 覆盖想增强的方法;
- 对于不想增强的方法,直接调用目标对象(被增强对象)的方法。
包装模式例子:
class MyConnection implements Connection{ // step 1
private Connection conn; // step 2
public MyConnection(Connection conn){ // step 3
this.conn = conn;
}
public void close(){ // step 4
list.add(this.conn);
}
// step 5
@Override
public void commit() throws SQLException{
this.conn.commit(); // 调用的是 mysql 提供的 commit 方法
}
@Override
public void clearWarnings() throws SQLException{
this.conn.clearWarnings(); // 调用的是 mysql 提供的 clearWarnings 方法
}
/*
...
...
后面不想增强的方法均照 step 5 处理,极有可能代码量超大,这也是包装模式处理此类问题的缺点
*/
}使用经包装(装饰)后的conn对象:
MyConnection my = new MyConnection(conn);当我们用my这个链接对象时,它的close方法就是我们自己写的方法了。
下面代码时动态代理方式(这里仅做个记录):
proxyConn = (Connection) Proxy.newProxyInstance(this.getClass()
.getClassLoader(), conn.getClass().getInterfaces(),
new InvocationHandler() {
// 此处为内部类,当close方法被调用时将conn还回池中,其它方法直接执行
public Object invoke(Object proxy, Method method,
Object[] args) throws Throwable {
if (method.getName().equals("close")) {
pool.addLast(conn);
return null;
}
return method.invoke(conn, args);
}
});3. 常用开源数据库连接池(DataSource 接口的开源实现)
数据源 = 数据库连接池
常见开源数据库连接池有:
- DBCP 数据库连接池
- C3P0 数据库连接池
- Apache Tomcat 内置的连接池(用的是 apache DBCP)
3.1 Apache DBCP 数据源
若想用 Apache DBCP,应用程序应增加如下 2 个 jar 文件:
- Commons-dbcp.jar:连接池的实现
- Commons-pool.jar:连接池实现的依赖库
下面是 dbcp-1.2.2 开发包中的 dbcpconfig.properties文件(实验时,需将该文件 copy 到 src 目录下),其作用同以前我们自己写的 db.properties 一样,是存放配置 dbcp 连接哪种数据库、url、用户名、密码等信息的一种配置文件。如下:
#连接设置
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbc
username=root
password=
#<!-- 初始化连接 -->
initialSize=10
#最大连接数量
maxActive=50
#<!-- 最大空闲连接 -->
maxIdle=20
#<!-- 最小空闲连接 -->
minIdle=5
#<!-- 超时等待时间以毫秒为单位 6000毫秒/1000等于60秒 -->
maxWait=60000
#JDBC驱动建立连接时附带的连接属性属性的格式必须为这样:[属性名=property;]
#注意:"user" 与 "password" 两个属性会被明确地传递,因此这里不需要包含他们。
connectionProperties=useUnicode=true;characterEncoding=utf8
#指定由连接池所创建的连接的自动提交(auto-commit)状态。
defaultAutoCommit=true
#driver default 指定由连接池所创建的连接的只读(read-only)状态。
#如果没有设置该值,则“setReadOnly”方法将不被调用。(某些驱动并不支持只读模式,如:Informix)
defaultReadOnly=
#driver default 指定由连接池所创建的连接的事务级别(TransactionIsolation)。
#可用值为下列之一:(详情可见javadoc。)NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
defaultTransactionIsolation=READ_COMMITTED重新设置 JdbcUtils.java,用连接池的方式:
package cn.wk.utils;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
public class JdbcUtils_DBCP {
private static DataSource ds = null;
static {
try {
// 读配置文件 dbcpconfig.properties
InputStream in = JdbcUtils_DBCP.class.getClassLoader()
.getResourceAsStream("dbcpconfig.properties");
Properties prop = new Properties();
prop.load(in);
BasicDataSourceFactory factory = new BasicDataSourceFactory();
ds = factory.createDataSource(prop);
} catch (Exception e) {
throw new ExceptionInInitializerError(e); // 异常转换成错误
}
}
public static Connection getConnection() throws SQLException {
return ds.getConnection(); // dbcp conn.close() commit()
}
public static void release(Connection conn, Statement st, ResultSet rs) {
// 模板代码
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
rs = null;
}
if (st != null) {
try {
st.close();
} catch (Exception e) {
e.printStackTrace();
}
st = null;
}
if (conn != null) {
try {
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}3.2 C3P0 数据源 (Spring 内置数据源)
C3P0 的jar包在c3p0-0.9.2-pre1中,导入如下2个jar包:
- c3p0-0.9.2-pre1.jar
- mchange-commons-0.2.jar
C3P0数据源配置文件名为c3p0-config.xml,可放在src目录下,C3P0自己会找到它。
c3p0-config.xml例子如下:
<c3p0-config>
<default-config>
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/day16</property>
<property name="user">root</property>
<property name="password">root</property>
<property name="initialPoolSize">10</property>
<property name="maxIdleTime">30</property>
<property name="maxPoolSize">20</property>
<property name="minPoolSize">5</property>
<property name="maxStatements">200</property>
</default-config>
<named-config name="mysql">
<property name="acquireIncrement">50</property>
<property name="initialPoolSize">100</property>
<property name="minPoolSize">50</property>
<property name="maxPoolSize">1000</property><!-- intergalactoApp adopts a different approach to configuring statement caching -->
<property name="maxStatements">0</property>
<property name="maxStatementsPerConnection">5</property>
</named-config>
<named-config name="oracle">
<property name="acquireIncrement">50</property>
<property name="initialPoolSize">100</property>
<property name="minPoolSize">50</property>
<property name="maxPoolSize">1000</property><!-- intergalactoApp adopts a different approach to configuring statement caching -->
<property name="maxStatements">0</property>
<property name="maxStatementsPerConnection">5</property>
</named-config>
</c3p0-config>最上面的<default-config>是默认配置,使用方法如下:
ComboPooledDataSource ds = new ComboPooledDataSource();若想用<named-config name="oracle">的配置,使用方法如下:
ComboPooledDataSource ds = new ComboPooledDataSource("oracle");看起来非常方便。
完整的 C3P0 连接建立代码JdbcUtils_C3P0如下:
package cn.wk.utils;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import com.mchange.v2.c3p0.ComboPooledDataSource;
public class JdbcUtils_C3P0 {
private static ComboPooledDataSource ds = null;
static {
try {
ds = new ComboPooledDataSource();
} catch (Exception e) {
throw new ExceptionInInitializerError(e); // 异常转换成错误
}
}
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
public static void release(Connection conn, Statement st, ResultSet rs) {
// 模板代码
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
rs = null;
}
if (st != null) {
try {
st.close();
} catch (Exception e) {
e.printStackTrace();
}
st = null;
}
if (conn != null) {
try {
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}测试代码:
public class Demo4 {
public static void main(String[] args) throws SQLException,
InterruptedException {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try {
conn = JdbcUtils_C3P0.getConnection();
System.out.println(conn.getClass().getName());
} finally {
JdbcUtils_C3P0.release(conn, st, rs);
}
}
}4. 编写自己的 JDBC 框架
4.1 元数据 - DataBaseMetaData
元数据:数据库、表、列的定义信息。
Connection.getDatabaseMetaData()
DataBaseMetaData对象
- getURL():返回一个String类对象,代表数据库的URL。
- getUserName():返回连接当前数据库管理系统的用户名。
- getDatabaseProductName():返回数据库的产品名称。
- getDatabaseProductVersion():返回数据库的版本号。
- getDriverName():返回驱动驱动程序的名称。
- getDriverVersion():返回驱动程序的版本号。
- isReadOnly():返回一个boolean值,指示数据库是否只允许读操作。
ParameterMetaData对象,获取 sql 语句参数的元数据。
以上2个元数据对象例子如下:
public class Demo5 {
public static void main(String[] args) throws SQLException {
Connection conn = JdbcUtils_C3P0.getConnection();
// 获取数据库的元数据
DatabaseMetaData meta = conn.getMetaData();
System.out.println(meta.getDatabaseProductName());
// 获取参数元数据
String sql = "insert into user(id,name) values(?,?)";
PreparedStatement st = conn.prepareStatement(sql);
ParameterMetaData para_meta = st.getParameterMetaData();
System.out.println(para_meta.getParameterCount());
System.out.println(para_meta.getParameterType(1)); // mysql不支持获得类型,抛异常
}
}ResultSetMetaData对象(重要,后面案例用到),结果集元数据:
- getColumnCount() 返回resultset对象的列数
- getColumnName(int column) 获得指定列的名称
- getColumnTypeName(int column) 获得指定列的类型
4.2 做自己的 jdbc 框架
准备:
模拟环境,先弄一个cn.wk.domain.Account的javabean:
package cn.wk.domain;
public class Account {
private int id;
private String name;
private double money;
public int getId() {return id;}
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(String name) {this.name = name;}
public double getMoney() {return money;}
public void setMoney(double money) {this.money = money;}
}dao 层方法大致代码:
注意到:crud 变化的是 sql 和 st.set 其余代码均相同
public void add(Account a) throws SQLException{
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try {
conn = JdbcUtils_DBCP.getConnection();
String sql = "(?,?,?)";
st.setInt(1, a.getId());
st.setString(2, a.getName());
st.setDouble(3, a.getMoney());
st.executeUpdate();
} finally {
JdbcUtils_DBCP.release(conn, st, rs);
}
}
public void delete(int id) throws SQLException{
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try {
conn = JdbcUtils_DBCP.getConnection();
String sql = "delete from where id=?";
st.setInt(1, id);
st.executeUpdate();
} finally {
JdbcUtils_DBCP.release(conn, st, rs);
}
}现在要做优化,抽出相同的部分。
重写了cn.wk.utils.JdbcUtils,重点在该工具类的release方法的后面, 涉及到以下知识点:
自己 = 框架编写者
- 自己的框架提供个接口(处理器),供用户填写;
- 自己写好了常用的处理器实现;
- 使用元数据;
- 使用反射技术,根据结果集字段名向对应的bean的域中写入数据。
package cn.wk.utils;
import java.io.InputStream;
import java.lang.reflect.Field;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.ResultSetMetaData;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
import javax.sql.DataSource;
import org.apache.commons.dbcp.BasicDataSourceFactory;
public class JdbcUtils {
private static DataSource ds = null;
static {
try {
// 读配置文件 dbcpconfig.properties
InputStream in = JdbcUtils.class.getClassLoader()
.getResourceAsStream("dbcpconfig.properties");
Properties prop = new Properties();
prop.load(in);
BasicDataSourceFactory factory = new BasicDataSourceFactory();
ds = factory.createDataSource(prop);
} catch (Exception e) {
throw new ExceptionInInitializerError(e); // 异常转换成错误
}
}
public static Connection getConnection() throws SQLException {
return ds.getConnection(); // dbcp conn.close() commit()
}
public static void release(Connection conn, Statement st, ResultSet rs) {
// 模板代码
if (rs != null) {
try {
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
rs = null;
}
if (st != null) {
try {
st.close();
} catch (Exception e) {
e.printStackTrace();
}
st = null;
}
if (conn != null) {
try {
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/* 抽取 增删改 的公共代码 */
// add delete update 都调用下面方法,变化的部分 sql , params
// String sql="insert into account(id,name,money) values(?,?,?)";
// object[]{1,"aaa","1000"}
public static void update(String sql, Object params[]) throws SQLException {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try {
conn = getConnection();
st = conn.prepareStatement(sql);
for (int i = 0; i < params.length; i++)
st.setObject(i + 1, params[i]);
st.executeUpdate();
} finally {
release(conn, st, rs);
}
}
// 想替换掉所有 查询
public static Object query(String sql, Object params[],
ResultSetHandler handler) throws SQLException {
Connection conn = null;
PreparedStatement st = null;
ResultSet rs = null;
try {
conn = getConnection();
st = conn.prepareStatement(sql);
for (int i = 0; i < params.length; i++)
st.setObject(i + 1, params[i]);
rs = st.executeQuery(); // 接下来, 框架制作者不知道该怎样处理 rs
// 方法: 对外暴露个接口,让调用者实现那个接口(handler),我们用客户所实现的接口处理 rs
// 调用用户传来的 handler
return handler.handler(rs);
} finally {
release(conn, st, rs);
}
}
}
// 设计一个接口,对外暴露
interface ResultSetHandler {
public Object handler(ResultSet rs); // 让用户实现这个方法
}
// 框架作者根据现实情况,提前写好一些处理器
class BeanHandler implements ResultSetHandler {
// 不知道 bean 是啥, 就定义一个变量接收,且用构造函数提供对外访问方式
private Class clazz;
public BeanHandler(Class clazz) {
this.clazz = clazz;
}
@Override
public Object handler(ResultSet rs) {
try {
if (!rs.next())
return null;
// 创建出要封装结果集的 bean
Object bean = this.clazz.newInstance();
// 通过元数据技术获知 rs 里有啥
ResultSetMetaData meta = rs.getMetaData();
int colNum = meta.getColumnCount();
for (int i = 0; i < colNum; i++) {
String name = meta.getColumnName(i + 1); // 结果集每列列名 id
Object value = rs.getObject(name); // 1
// 通过 name,反射出 bean 上与 name对应的属性
Field f = bean.getClass().getDeclaredField(name);
f.setAccessible(true); // 强制访问私有元素
f.set(bean, value);
}
return bean;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
// 返回包含 bean 的 list 集合
class BeanListHandler implements ResultSetHandler {
private Class clazz;
public BeanListHandler(Class clazz) {
this.clazz = clazz;
}
@Override
public Object handler(ResultSet rs) {
List list = new ArrayList();
try {
ResultSetMetaData meta = rs.getMetaData();
int count = meta.getColumnCount();
while (rs.next()) {
Object bean = this.clazz.newInstance();
for (int i = 0; i < count; i++) {
String name = meta.getColumnName(i + 1);
Object value = rs.getObject(name);
Field f = bean.getClass().getDeclaredField(name); // 反射获取域
f.setAccessible(true);
f.set(bean, value);
}
list.add(bean);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
return list;
}
}模拟使用该框架的 dao 代码:
package cn.wk.utils;
import java.sql.SQLException;
import org.junit.Test;
import cn.wk.domain.Account;
// 假设这是 Dao
// 注意到:crud 变化的是 sql 和 st.set 其余代码均相同
public class Demo7 {
@Test
public void test() throws SQLException {
List<?> list = getAll();
System.out.println(list.size());
}
public void add(Account a) throws SQLException {
String sql = "insert into account(name,money) values(?,?)";
Object params[] = { a.getName(), a.getMoney() };
JdbcUtils.update(sql, params);
}
public void delete(int id) throws SQLException {
String sql = "delete from account where id=?";
Object params[] = { id };
JdbcUtils.update(sql, params);
}
public void update(Account a) throws SQLException {
String sql = "update account set name=?, money=? where id=?";
Object params[] = { a.getName(), a.getMoney(), a.getId() };
JdbcUtils.update(sql, params);
}
public Account find(int id) throws SQLException {
String sql = "select * from account where id=?";
Object params[] = { id };
return (Account) JdbcUtils.query(sql, params, new BeanHandler(
Account.class));
}
public List getAll() throws SQLException {
String sql = "select * from account";
Object params[] = {};
return (List) JdbcUtils.query(sql, params, new BeanListHandler(
Account.class));
}
}















热门排行
今日推荐






热门手游
-
战地世界免费版

版本:v1.5
大小:136.58MB
日期:2024-11-05
-
真实靶场训练营完整版

版本:v1.4
大小:39.70MB
日期:2024-11-05
-
绝地战场之求生安卓版

版本:v1.0.5
大小:21.72MB
日期:2024-11-05
-
花朵射手免费版

版本:v1.6.1
大小:35.78MB
日期:2024-11-05
-
僵尸城市生存大战正版

版本:v1.5
大小:84.00MB
日期:2024-11-05
-
夺宝兵团免费版

版本:v1.3.6
大小:12.85MB
日期:2024-11-05