使用sqoop将mysql数据导入到hadoop
时间:2022-03-14 03:34
hadoop的安装配置这里就不讲了。
Sqoop的安装也很简单。 完成sqoop的安装后,可以这样测试是否可以连接到mysql(注意:mysql的jar包要放到 SQOOP_HOME/lib 下): sqoop list-databases --connect jdbc:mysql://192.168.1.109:3306/ --username root --password 19891231 结果如下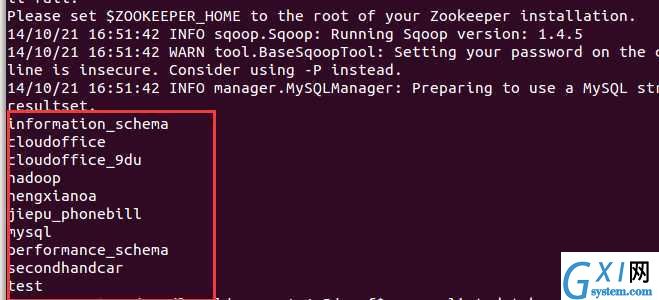 即说明sqoop已经可以正常使用了。
下面,要将mysql中的数据导入到hadoop中。
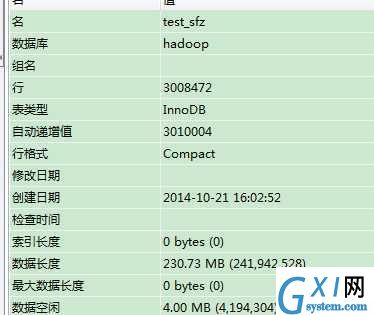
我准备的是一个300万条数据的身份证数据表:
即说明sqoop已经可以正常使用了。
下面,要将mysql中的数据导入到hadoop中。
我准备的是一个300万条数据的身份证数据表:
 先启动hive(使用命令行:hive 即可启动)
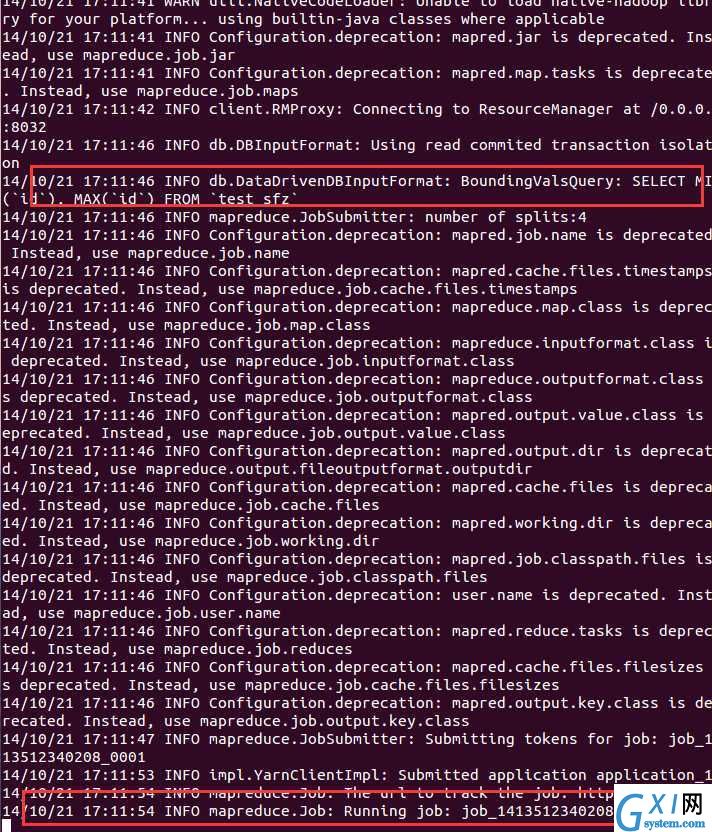
然后使用sqoop导入数据到hive:
sqoop import --connect jdbc:mysql://192.168.1.109:3306/hadoop --username root --password 19891231 --table test_sfz --hive-import
sqoop 会启动job来完成导入工作。
先启动hive(使用命令行:hive 即可启动)
然后使用sqoop导入数据到hive:
sqoop import --connect jdbc:mysql://192.168.1.109:3306/hadoop --username root --password 19891231 --table test_sfz --hive-import
sqoop 会启动job来完成导入工作。
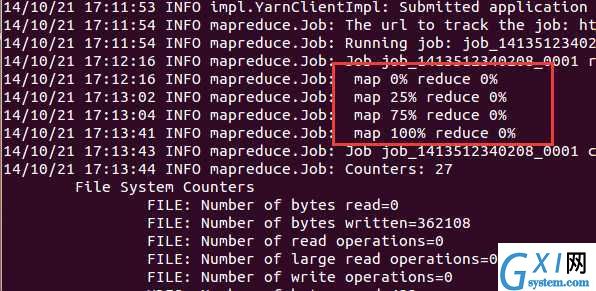 完成导入用了2分20秒,还是不错的。
在hive中可以看到刚刚导入的数据表:
完成导入用了2分20秒,还是不错的。
在hive中可以看到刚刚导入的数据表:
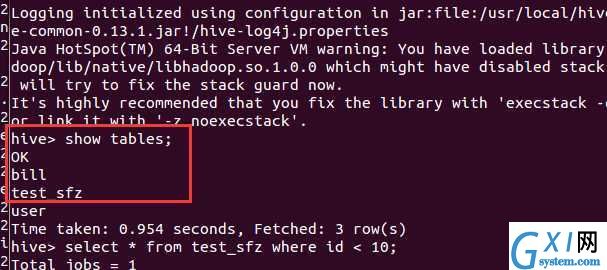 我们来一句sql测试一下数据:
select * from test_sfz where id < 10;
我们来一句sql测试一下数据:
select * from test_sfz where id < 10;
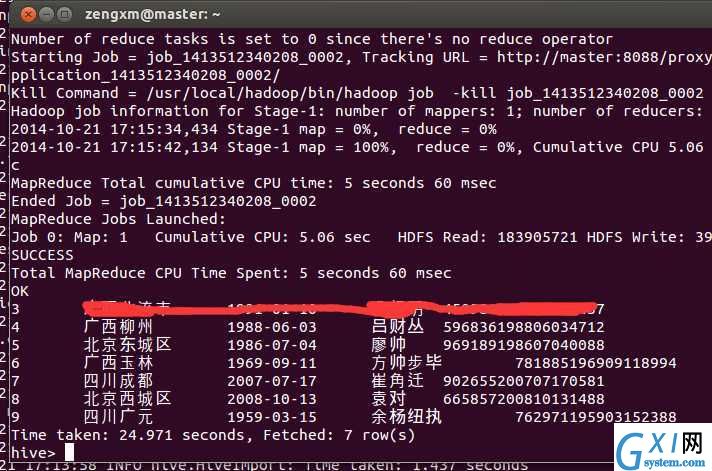 可以看到,hive完成这个任务用了将近25秒,确实是挺慢的(在mysql中几乎是不费时间),但是要考虑到hive是创建了job在hadoop中跑,时间当然多。
可以看到,hive完成这个任务用了将近25秒,确实是挺慢的(在mysql中几乎是不费时间),但是要考虑到hive是创建了job在hadoop中跑,时间当然多。
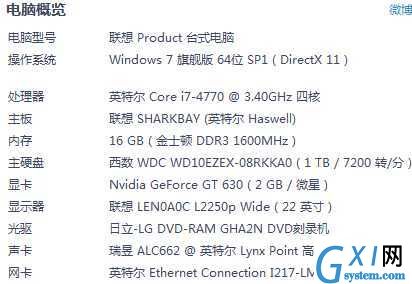
接下来,我们会对这些数据进行复杂查询的测试: 我机子的配置如下:
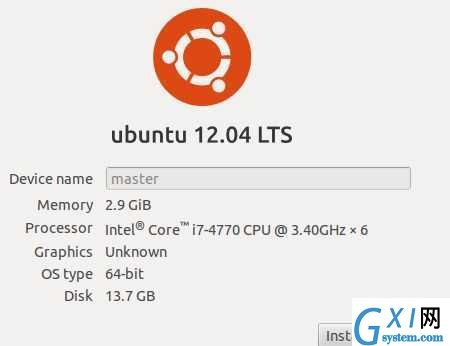
 hadoop 是运行在虚拟机上的伪分布式,虚拟机OS是ubuntu12.04 64位,配置如下:
hadoop 是运行在虚拟机上的伪分布式,虚拟机OS是ubuntu12.04 64位,配置如下:
TEST 1 计算平均年龄
测试数据:300.8 W 1. 计算广东的平均年龄 mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz where address like ‘广东%‘; 用时: 0.877s hive:select (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz where address like ‘广东%‘; 用时:25.012s 2. 对每个城市的的平均年龄进行从高到低的排序 mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz GROUP BY address order by ageAvge desc; 用时:2.949s hive:select address, (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz GROUP BY address order by ageAvge desc; 用时:51.29s 可以看到,在耗时上面,hive的增长速度较mysql慢。TEST 2
测试数据:1200W mysql 引擎: MyISAM(为了加快查询速度) 导入到hive: 1. 计算广东的平均年龄
mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like ‘广东%‘;
用时: 5.642s
hive:select (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like ‘广东%‘;
用时:168.259s
2. 对每个城市的的平均年龄进行从高到低的排序
mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc;
用时:11.964s
hive:select address, (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc;
用时:311.714s
1. 计算广东的平均年龄
mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like ‘广东%‘;
用时: 5.642s
hive:select (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like ‘广东%‘;
用时:168.259s
2. 对每个城市的的平均年龄进行从高到低的排序
mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc;
用时:11.964s
hive:select address, (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc;
用时:311.714s
TEST 3
测试数据:2000W mysql 引擎: MyISAM(为了加快查询速度) 导入到hive: (这次用的时间很短!可能是因为TEST2中的导入时,我的主机在做其他耗资源的工作..) 1. 计算广东的平均年龄 mysql:select (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like ‘广东%‘; 用时: 6.605s hive:select (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 where address like ‘广东%‘; 用时:188.206s 2. 对每个城市的的平均年龄进行从高到低的排序 mysql:select address, (sum(year(NOW()) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用时:19.926s hive:select address, (sum(year(‘2014-10-01‘) - SUBSTRING(borth,1,4))/count(*)) as ageAvge from test_sfz2 GROUP BY address order by ageAvge desc; 用时:411.816s
















热门排行
今日推荐






热门手游
-
星之后裔2:吠陀骑士官方版

版本:v1.0.0
大小:168.37MB
日期:2024-10-11
-
森林王国手机版

版本:v1.16
大小:262.89MB
日期:2024-10-11
-
永夜英雄安卓版

版本:v0.2
大小:46.52MB
日期:2024-10-11
-
刀剑仙域:浩龙情缘安卓版

版本:v1.0.2
大小:268.74MB
日期:2024-10-11
-
侏罗纪世界2失落王国正版

版本:v1.0.28
大小:5.78MB
日期:2024-10-11
-
欧呜欧手机版

版本:v1.0
大小:147.16MB
日期:2024-10-11