InnoDB之锁机制
时间:2022-03-14 03:55
先插播条广告,看到某度在做推广,一分钱领取手套,冬天啦,大家速度~~~ 前两天听了姜老大关于InnoDB中锁的相关培训,刚好也在看这方面的知识,就顺便利用时间把这部分知识做个整理,方便自己理解。主要分为下面几个部分: 1. InnoDB同步机制 InnoDB存储引擎有两种同步机制选择,一种是mutex,其是完全的互斥方法。另一种是rw-lock,可以给临界资源加上s-latch或者x-latch。其中s-latch允许并发的读取操作,而x-latch是完全的互斥操作。 mutex是基于test-and-set机制实现的,在其基础上做了优化。具体的流程为: 1、线程调用test-and-set返回1,说明其他线程已经持有了这把锁,此时先进行自旋。自旋时间大约为20us 2、再次获取mutex,如果还是不能获取到就放入wait array中,等待被唤醒。 2. Lock和Latch的区别
| Lock | Latch | |
| 锁定对象 | 事务 | 线程 |
| 锁定持续时间 | 整个事务过程 | 临界资源持有过程 |
| 模式 | 行锁、表锁、意向锁 | 读写锁、互斥量 |
| 死锁 | 智能死锁检测 | 无死锁检测与处理机制 |
- Flush tables with read lock;
- select * from user where name = "libis" for update; 其中name字段不是user表的索引
 为什么会这样?那可以这样想,如果事务B不会被事务A阻塞,会发生什么?假设事务B没有被事务A阻塞,事务B先执行了一次 select * from user where name = "libis" for update得到了一行记录,此时事务A正好了修改了这条记录,然后提交了,事务B再次执行上述select语句就肯定会得到不同的记录,这就违背了事务隔离性的要求。意向锁就是为了解决这样的问题。
事务A修改user表的记录r,会给记录r上一把X行锁,同时会给user表上一把意向排他锁(IX),这时事务B要给user表上表级排他锁就会被阻塞。意向锁通过这种方式实现了行锁和表锁共存且满足事务隔离性的要求。
4. 对可重复读和幻读的理解
(1)什么是不可重复读?什么是幻读?两者的区别是什么
不可重复读重点在同一个事务多次读同一条记录的时候,出现读到的数据不一致的情况。InnoDB通过MVCC的方式避免了不可重复读,即一致性的非锁定读。
幻读重点在同一个事务多次执行相同的SQL,可能返回之前不存在的行,或者之前存在的行之后不存在了。InnoDB使用Next-key Lock算法避免了幻读,即一致性的锁定读。
默认情况下,InnoDB使用一致性的非锁定读,即读取不会被阻塞。然而有些情况下用户希望通过锁定读取的方式保证数据的一致性,这时可以通过语法lock in share mode或for update主动对读取进行加锁操作,称这种方式为一致性的锁定读。
(2)InnoDB如何避免不可重复读?
见另一篇博文:InnoDB之MVCC机制与不可重复读
(3)InnoDB如何避免幻读?
在了解具体实现之前,首先对InnoDB中锁的算法有一定了解,InnoDB提供了三种锁算法:
为什么会这样?那可以这样想,如果事务B不会被事务A阻塞,会发生什么?假设事务B没有被事务A阻塞,事务B先执行了一次 select * from user where name = "libis" for update得到了一行记录,此时事务A正好了修改了这条记录,然后提交了,事务B再次执行上述select语句就肯定会得到不同的记录,这就违背了事务隔离性的要求。意向锁就是为了解决这样的问题。
事务A修改user表的记录r,会给记录r上一把X行锁,同时会给user表上一把意向排他锁(IX),这时事务B要给user表上表级排他锁就会被阻塞。意向锁通过这种方式实现了行锁和表锁共存且满足事务隔离性的要求。
4. 对可重复读和幻读的理解
(1)什么是不可重复读?什么是幻读?两者的区别是什么
不可重复读重点在同一个事务多次读同一条记录的时候,出现读到的数据不一致的情况。InnoDB通过MVCC的方式避免了不可重复读,即一致性的非锁定读。
幻读重点在同一个事务多次执行相同的SQL,可能返回之前不存在的行,或者之前存在的行之后不存在了。InnoDB使用Next-key Lock算法避免了幻读,即一致性的锁定读。
默认情况下,InnoDB使用一致性的非锁定读,即读取不会被阻塞。然而有些情况下用户希望通过锁定读取的方式保证数据的一致性,这时可以通过语法lock in share mode或for update主动对读取进行加锁操作,称这种方式为一致性的锁定读。
(2)InnoDB如何避免不可重复读?
见另一篇博文:InnoDB之MVCC机制与不可重复读
(3)InnoDB如何避免幻读?
在了解具体实现之前,首先对InnoDB中锁的算法有一定了解,InnoDB提供了三种锁算法:
- Record Lock : 单个行记录上的锁
- Gap Lock:锁定一个范围,但不包括记录本身
- Next-Key Lock:锁定一个范围,包括记录本身
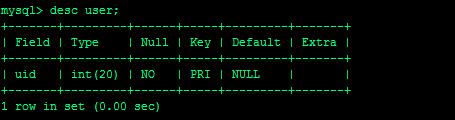 里面有三条记录:
里面有三条记录:
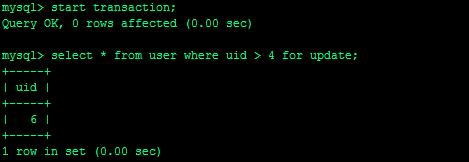
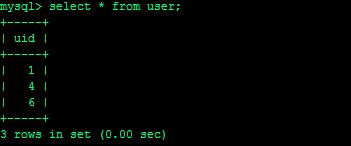 开启事务A,执行select * from user where uid > 4 for update,没有commit :
开启事务A,执行select * from user where uid > 4 for update,没有commit :
 开启另一个事务B,执行insert into user values (5)
开启另一个事务B,执行insert into user values (5)
 会发现这个事务会被夯住,执行下面查询数据库锁的语句可以看到,事务B被事务A阻塞住了,即事务B在等事务持有的锁:
会发现这个事务会被夯住,执行下面查询数据库锁的语句可以看到,事务B被事务A阻塞住了,即事务B在等事务持有的锁:
 再通过执行show engine innodb status查看具体的锁信息,可以看到事务A上了一把锁锁住了某个gap导致事务B等待:
再通过执行show engine innodb status查看具体的锁信息,可以看到事务A上了一把锁锁住了某个gap导致事务B等待:
 这会大家就应该知道Next-Key Lock的意义了吧,它锁住的是一个范围,而不是某一条记录,就拿上例来说,事务A锁住的是[4,6),[6,无穷大)这两个范围,因此向user中插入5是不可行的,直至事务A结束事务B才能执行成功,这样就可以避免幻读。
5. InnoDB中锁的实现机制
(1)页锁对象 + 位图 的实现方式
InnoDB中锁是根据页的组织形式进行管理的,行锁在InnoDB中的定义如下:
这会大家就应该知道Next-Key Lock的意义了吧,它锁住的是一个范围,而不是某一条记录,就拿上例来说,事务A锁住的是[4,6),[6,无穷大)这两个范围,因此向user中插入5是不可行的,直至事务A结束事务B才能执行成功,这样就可以避免幻读。
5. InnoDB中锁的实现机制
(1)页锁对象 + 位图 的实现方式
InnoDB中锁是根据页的组织形式进行管理的,行锁在InnoDB中的定义如下:
struct lock_rec_struct{
ulint space
ulint page_no
ulint n_bits
}
其中space/page_no可以唯一决定一个页,nbits是一个位图。因此要查看某行记录是否上锁,只需要根据space/page_no找到对应的页,然后根据位图中对应位置是否是1来决定此行记录是否上锁。
给某条记录上锁,首先查看记录所在页是否已经有锁对象,如果锁对象已经存在,则将位图上对应位置置1。如果不存在,则生成一个锁对象,然后将位图对应位置置1;
这种锁的实现机制可以最大程度地重用锁对象,节省系统资源,不存在锁升级的问题。可想而知,如果每个行锁都生成一个锁对象,将会导致严重的性能损耗,比如接近于全表扫描的查询就会生成大量的锁对象,内存开销将会很大。位图的方式很好地避免了这个问题。
(2)通过事务或(space,page_no)再Hash的方式组织页锁对象
InnoDB提供了两种方式对行锁进行访问:
通过事务中的trx_t变量访问。一个事务可能在不同页上有多个行锁,因此需要变量trx_locks将一个事务中的所有行锁信息进行链接,这样就可以很快地查看一个事务中的所有锁对象。
通过space/page_no访问。InnoDB提供了一个全局变量lock_sys_struct来方便查询行锁信息。lock_sys_struct包含一个HashTable,Hash的key是space/page_no,value是锁对象lock_rec_struct
6. InnoDB索引组织表的加锁过程
InnoDB是通过索引B+树进行组织的,因此对记录的加锁实际上是对索引的加锁。总的里说,加锁流程如下:
(1)通过主键进行加锁的语句,仅对聚焦索引记录进行加锁
(2)通过辅助索引进行加锁的语句,先对辅助索引进行加锁,再对聚焦索引记录进行加锁
(3)通过辅助索引进行加锁的语句,还可能需要对下一个辅助索引进行加锁(需要根据数据库的隔离级别而定)
详细的过程可以参考登博的博客:
7. 锁相关的运帷操作
(1)show engine innodb status; (2)select r.trx_id waiting_trx_id , r.trx_mysql_thread_id waiting_thread, r.trx_query waiting_query , b.trx_id blocking_trx_id, b.trx_mysql_thread_id blocking_thread , b.trx_query blocking_query from information_schema.innodb_lock_waits w inner join information_schema.innodb_trx b on b.trx_id = w.blocking_trx_id inner join information_schema.innodb_trx r on r.trx_id = w.requesting_trx_id;
















热门排行
今日推荐






热门手游
-
库比德射击Sandbox破解版

版本:v7.1
大小:148.67MB
日期:2024-10-12
-
战争炮火:军事模拟免费版

版本:v1.7.10
大小:313.57MB
日期:2024-10-12
-
自由射击模拟安卓版

版本:v1.0.0
大小:152.71MB
日期:2024-10-12
-
使命召唤16正版

版本:v0.2.4
大小:447.37MB
日期:2024-10-12
-
疯狂植物战争手机版

版本:v1.0
大小:59.23MB
日期:2024-10-12
-
模拟功夫格斗正版

版本:v1.0
大小:35.99MB
日期:2024-10-12