浅谈MySQL索引背后的数据结构及算法
时间:2022-03-10 17:05
摘要
本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题。特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 也各不相同,因此MySQL数据库支持多种索引类型,如BTree索引,哈希索引,全文索引等等。为了避免混乱,本文将只关注于BTree索引,因为这是 平常使用MySQL时主要打交道的索引,至于哈希索引和全文索引本文暂不讨论。
文章主要内容分为四个部分。
第一部分主要从数据结构及算法理论层面讨论MySQL数据库索引的数理基础。
第二部分结合MySQL数据库中MyISAM和InnoDB数据存储引擎中索引的架构实现讨论聚集索引、非聚集索引及覆盖索引等话题。
第三部分根据上面的理论基础,讨论MySQL中高性能使用索引的策略。
摘要
数据结构及算法基础
索引的本质
B-Tree和B+Tree
为什么实用B-Tree(B+Tree)
MySQL索引实现
MyISAM索引实现
InnoDB索引实现
索引使用策略及优化
示例数据库
最左前缀原理与相关优化
索引选择性与前缀索引
InnoDB的主键选择与插入优化
后记
参考文献
数据结构及算法基础
索引的本质
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。提取句子主干,就可以得到索引的本质:索引是数据结构。
我们知道,数据库查询是数据库的最主要功能之一,例如下面的SQL语句:
SELECT * FROM my_table WHERE col2 = ‘77‘
可以从表“my_table”中获得“col2”为“77”的数据记录。
我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),遍历“my_table”然后逐行匹配“col2”的值是否是“77”,这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
看一个例子:
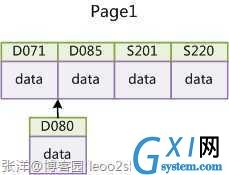
图14
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了 很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
后记
这篇文章断断续续写了半个月,主要内容就是上面这些了。不可否认,这篇文章在一定程度上有纸上谈兵之嫌,因为我本人对MySQL的使用属于菜鸟级别,更没有太多数据库调优的经验,在这里大谈数据库索引调优有点大言不惭。就当是我个人的一篇学习笔记了。
其实数据库索引调优是一项技术活,不能仅仅靠理论,因为实际情况千变万化,而且MySQL本身存在很复杂的机制,如查询优化策略和各种引擎的实现差 异等都会使情况变得更加复杂。但同时这些理论是索引调优的基础,只有在明白理论的基础上,才能对调优策略进行合理推断并了解其背后的机制,然后结合实践中 不断的实验和摸索,从而真正达到高效使用MySQL索引的目的。
另外,MySQL索引及其优化涵盖范围非常广,本文只是涉及到其中一部分。如与排序(ORDER BY)相关的索引优化及覆盖索引(Covering index)的话题本文并未涉及,同时除B-Tree索引外MySQL还根据不同引擎支持的哈希索引、全文索引等等本文也并未涉及。如果有机会,希望再对 本文未涉及的部分进行补充吧。
参考文献
[1] Baron Scbwartz等 著,王小东等 译;高性能MySQL(High Performance MySQL);电子工业出版社,2010
[2] Michael Kofler 著,杨晓云等 译;MySQL5权威指南(The Definitive Guide to MySQL5);人民邮电出版社,2006
[3] 姜承尧 著;MySQL技术内幕-InnoDB存储引擎;机械工业出版社,2011
[4] D Comer, Ubiquitous B-tree; ACM Computing Surveys (CSUR), 1979
[5] Codd, E. F. (1970). “A relational model of data for large shared data banks”. Communications of the ACM, , Vol. 13, No. 6, pp. 377-387
[6] MySQL5.1参考手册 – http://dev.mysql.com/doc/refman/5.1/zh/index.html
浅谈MySQL索引背后的数据结构及算法,布布扣,bubuko.com



























