数据库的本质、概念及其应用实践
时间:2022-03-10 17:35
今天这堂课,分为三个大点,正如标题所指出的,是讨论数据的本质、概念与应用实践。第一点本质的探讨是站在一个更高的高度来分析数据的产生以及各种使用场景,然后将数据相关的存储手段,作一个汇总讲解。而概念,则是一个串讲,主要放在关系数据库上,因为我们六月份公开课,也将以关系型数据库为主。第三点就是通过一些实例来巩固前面两点所讲的内容。
一、数据库的出现源起和本质
1.1 数据库的起源
想像一下我们的电脑,有目录,有文件,文件有大小,有位置,有格式,这个是有文件系统开始就有这个概念的,肯定在有一个地方,存储了这些文件的参数或者元数据,而在我们的日常生活中,每一个物体和人,都有其各自不同的特征,当一批量的这些可描述的人的特征,想要数据化存储起来的时候,也就需要有一种格式来保存。除了保存数据之外,我们还得对数据进行管理。这就是数据库出现的背景,并且随着使用场景的越加复杂,数据库本身也有了更多的衍生版本。
所以数据库起源于对数据的存储以及管理。
1.2数据库的使用场景
那么我们有几个问题, 基于大家目前的理解,第一个问题是有哪些需要保存的数据种类,有哪些存储方式呢?我们发散一点来想。
可以得到如下的情况:
A、在程序中自定义,比如数组,只保存在内存里,等程序停止了之后,数据就没有了。这样可以不可以?
在这个里面存储的反正是描述型数据,也可以是二进制数组。
B、保存在一个文本文件里可以不可以,有自己的格式,比如自定义的格式,比如XML,比如JSON格式
这里保存的,只能是描述型数据。
C、采用一些文件型数据库,比如支持SQL访问的文本数据库,比如Sqlite、比如Access
除了特定的数据类型,一般也只保存文本描述数据。
D、采用 MySQL 这样基于网络和可分布式的数据库系统。
用来保存较多数据量的用户数据、关系数据、交易数据,这些数据要实再快速查询更新。
E、当数据量大时,一台设备就不能满足要求,这就需要用到分布式数据库,可能是数据集群
F、采用 memcached 这样的软件保存着缓存的数据。
一般用于保存文本数据或者计数。
G、采用 fastdfs 这样的分布式文件系统来保存着文件数据。
不用于保存除文件本身描述之外的其他描述数据,用于保存大量的文件。
H、采用redis 这样的KVDB 软件来保存简单关系的描述数据,或者特定的结构。
比如用于保存微博数据,用KEY可以迅速定位到微博内容。
I、同KVDB类似的,大家有听过队列那几讲的同学吗?是不是也是特殊的数据存储手段呢?一边有人生产数据,一边有人消费数据。
J、用于保存地理关系数据,并提供运算。在英文里叫Spatial Data,也就是空间数据。Oracle最擅长,现在MySQL也有空间扩展。
http://dev.mysql.com/doc/refman/5.1/zh/spatial-extensions-in-mysql.html
K、而对于大量的,源源不断的海量数据,相对不那么规则的数据存储,我们可能存储在Hadoop系统中。
L、最后再谈一个场景,像百度这样的搜索引擎,他会把他的数据全放在MySQL里,然后去检索吗?显然不是。有自有的索引格式和支持分布式查询的系统 。
1.3数据库场景以及分类总结
总结一下:
A、在电脑时代以前,人类就产生了大量的信息,而电脑时代以来,更是产生了大量的数字化的数据。而这些数据库的保存的形式,从上面可以看到,依据不同的场景,不同的保存方式,是多种多样的。有仅在内存中保存,有在文件中保存,有专用严谨的数据库系统保存,也有不那么严谨的KVDB保存。
B、根据上面的各种存储场景,我们对数据,也做两个简单的分类,一个是结构化数据库和非结构化数据的分类,当然,还有再加一种半结构化数据的。所谓结构化,就是很规整地有属性的一种情况。像一个人,他有身高、体重、年龄,这个描述是结构化的,你给照一张照片,录一段声音,拍一段摄像,尽管这也是数据,但是不是结构化的。对于不同的这两类数据,存储方式也不相同,比如结构化数据是典型的二维表的结构。而非结构化数据就是只以原始数据的形式存储。
上面的场景,大多是结构化数据的处理场景,像文本数据库、MySQL数据库。而在fastdfs上,Hadoop上,就有大量的非结构化数据的存储。
C、根据数据量本身的大小,我们也可以做一个分类。或者特定的技术应用场景。
比如小数据量数据,我们可能为了方便,就以文本的方式来保存。而对于一个正规的提供服务的网站,像用户数据,比如优才网的用户数据,就会用MySQL数据库来保存,为了访问速度,也会用到memcached这样的缓存软件。也会用fastdfs来保存小文件。而当有大量的日志等数据量产生,需要进行数据分析的时候,比如每天的数据量以几百G,T来计的时候,就会用Hadoop 这样的软件。
所以,不同的数据量也使用不同的保存方式。小型数据、大中型数据、海量数据或者大数据。
D、第四个角度就是从上面可以看出,数据的存储方式,有很多类别,不同类别适用于不同的场景。数据库是很强大的,但是不是所有的场景都合适使用数据库。比如上面讲的全文检索的场景,一般需要用特定的存储,特定的索引方式。如果具体地讲,全文检索中,使用的一种索引,叫倒排索引。
二、数据库有哪些概念
好的,聊完了数据以及相关软件的一些使用场景,对于不同场景下使用不同软件有了概念。下面我们来介绍一下,在数据库的领域常用的 一些术语,这些术语,在我们的整个数据库学习中都要用到。
由于公开课的时间问题,我们主要交流一下基本概念,对于高级的概念,后面的公开课会持续地讲到。
2.1 数据库的基本概念
介绍我们下面数据库的这些概念时,我们以一个公司做为对比。
2.1.1、库
库,就相对于一个公司,下面几乎所有的概念都装在这个公司里的。
在使用数据库之前,我们得在数据库软件上创建数据库。
在 MySQL 里,同一个连接,只能附着在同一个库上,当然,只要权限允许,也可以实现跨库查询。
创建数据库的语法是
create database xxx;
只有root 用户能创建库。
2.1.2、表
表就相对于,公司的一个部门,这个部门管用户,那个部门管订单。就是一个又一个的表。
表由记录和字段组成。
字段表成的是表定义。
记录组成的是表数据。
?
CREATE TABLE `hstesttbl` (
`k` int(11) NOT NULL AUTO_INCREMENT,
`v` char(255) NOT NULL DEFAULT ‘‘,
PRIMARY KEY (`k`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
字段定义则有字段名,字段类型,是否为空,是否自增长,缺省值等。
记录则是实际的数据值,同一个表的记录的定义都是一样的。也就是说有相同的特征。
2.1.3、视图
视图类就相当于虚拟的项目小组,可以是同一个部门出来的,也可以是跨部门的。
视图之所以说是虚拟,因为没有实际存在的数据。无论是定义,还是数据,都是从别的表里组合起来的。
?
create view hsview as
select * from hstesttbl;
mysql> show tables;
+--------------------+
| Tables_in_hstestdb |
+--------------------+
| hstesttbl |
| hsview |
+--------------------+
2 rows in set (0.02 sec)
mysql> show create table hsview\G;
*************************** 1. row ***************************
View: hsview
Create View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `hsview` AS select `hstesttbl`.`k` AS `k`,`hstesttbl`.`v` AS `v` from `hstesttbl` |
从上面的命令可以看出,视图跟表的操作有很多相似。并且从表到视图还能修改字段名。
2.1.4、索引
索引就是相当于部门每个员工的一些用于快速找到员工的属性。比如职位,比如爱好,比如毕业学校。通过这些,就能将部门的人分类,每一次查询都能缩小结果集。
对表创建索引是,比如还是上面这个表, alter table hstesttbl add index(xxx);
2.1.5、键
键就相当于部门每个人的一些最快捷且唯一的联络方式,比如电话、邮箱,微信号,QQ号都是。
添加键跟添加索引,类似,删除键这里介绍一下,
比如:
alter table hstesttbl drop primary key;
2.1.6、权限
是指公司内部限制的一些纪律,比如公司外部人,是不能知道公司内部的一些事情的。
我们可以通过
grant ALL PRIVILEGES on dbname.* to ‘user‘@‘127.0.0.1‘ identified by ‘password‘ with grant option;
这样的语句给某用户授权,全权访问某个库。这个这个用户只能访问这个库,在没有获得更多授权的情况下。
上面说只有root用户能创建数据库,而对于上面的其他操作,比如创建表,添加视图,新建、删除索引和键,只要经过了上面的授权,就可以做了。
2.1.7、SQL
SQL就相当于公司的一些规定,指令。比如我们在公司里交流说,可以发布到生产环境了。听起来一句简单的话,包含着可能进行了产品确认,各种测试,可以由运维上线了。
SQL是我们同数据库打交道的指令。上面其实在讲各个概念时,已经都讲过了一些SQL命令,我想这里提几个点。
手写命令,非常重要,优才网要求自己的学员都要有手写命令的能力,不能离开phpmyadmin就没有办法干活。
SQL上面尽管介绍了这么多,我们对它进行一个分类,其实这个分类早有人做了。主要是为DDL、DML、DCL(当然还有一个TCL,我们今天不讲)。
(1)数据定义。(SQL DDL)用于定义SQL模式、基本表、视图和索引的创建和撤消操作。上面的,大多是DDL。
(2)数据操纵。(SQL DML)数据操纵分成数据查询和数据更新两类。数据更新又分成插入、删除、和修改三种操作。 这就是我们平常所熟知的增删改查操作。
(3)数据控制(DCL)。包括对基本表和视图的授权,完整性规则的描述,事务控制等内容。这个就是我们上面也有涉及,权限处理。
2.2 学术性的概念
?1、范式与冗余
–第一范式,列不可以分割,比如兴趣字段,它里面,可能写了篮球、电影等多项。原则上来讲,这个表是不满足第一范式的。应该专门建立一个用户兴趣表,有uid和兴趣。然后一个人有多条记录。
所以在数据库字段定义时,需要显式地指明数据类型,除了文本类型之外,你很难往一个字段里附加多个信息。
–第二范式,主键决定了其他全部属性,比如一个班级学生表,一个学号,决定了学生其他的信息,比如有一个表,里面有学号、学院编号、学生姓名、年龄、学院、院长。学号和学院编号是主键,看起来没有错,学生在这个学院编号里,决定了哪个学院,院长是谁谁谁。不过这是不满足第二范式的,因为学院和院长不是由学号这个主键来决定的,而是由学院编号来决定的。所以要分拆。
–和三范式,其他属性全由主键决定, 比如还是上面这个表,里面有学号、学院编号、学生姓名、年龄、学院、院长。学号是主键,看起来没有错,学生在这个学院里,院长是谁谁谁。不过这是不满足第二范式的,因为院长不是由学号这个主键来决定的,而是由学院来决定的。所以要分拆。
?2、ACID:
–原子性 (Atomicity) , 不可中间失败。比如说,我们买东西,一边是买家付款,从买家账户扣除,另一边是存钱入卖家账户,这分了两步,这不是原子的。因为可能中间失败。比如扣钱成功,存钱未成功。
–一致性(Consistency),还是上面这个例子,交易完成后,数据一致,收支相抵。不能一边多,一边少。
–隔离性(Isolation),避免并发混乱,很多数据,一个客户访问时没有问题,多个用户在高并发时访问,也要满足数据不会错乱。
–持久性(Durability),永久保存,就是不要丢失。不能一关机没有了,即使丢一条也不成。
2.3 更多高级术语
1、存储引擎 、事务、复合索引、连接池、备份、恢复
2、主从复制、行锁定、表锁定、慢查询、二进制日志、临时表、内容分发、同步、数据库分区、分库、分表、水平拆分、垂直拆分
这更多的高级术语,我们在后面再交流,或者在全栈工程师课程中再交流。
三、各种数据库的关系、实践
3.1、自制简单文本格式(甚至在PHP中,用数据保存配置)
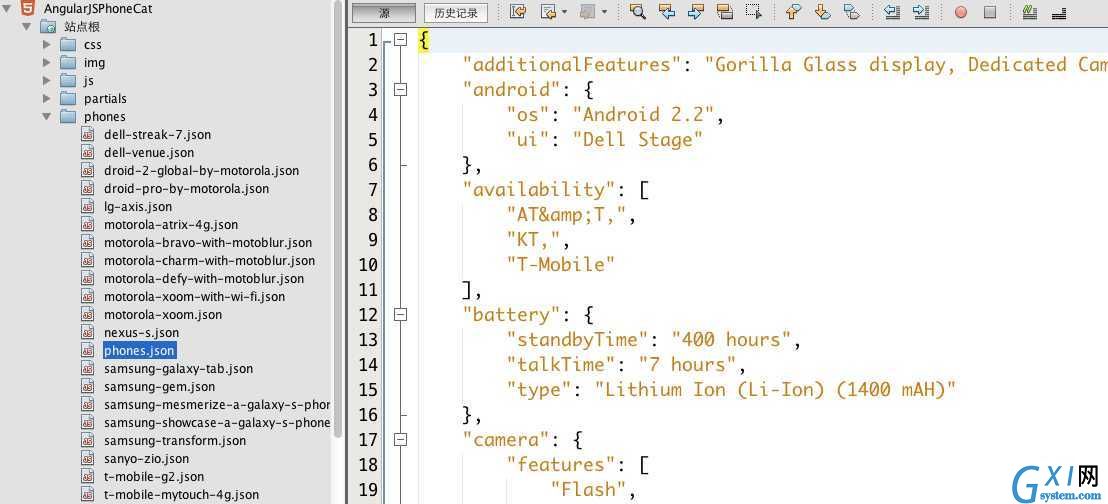
A、比如有一个AngularJS的示例项目,就用json保存示例数据的格式。
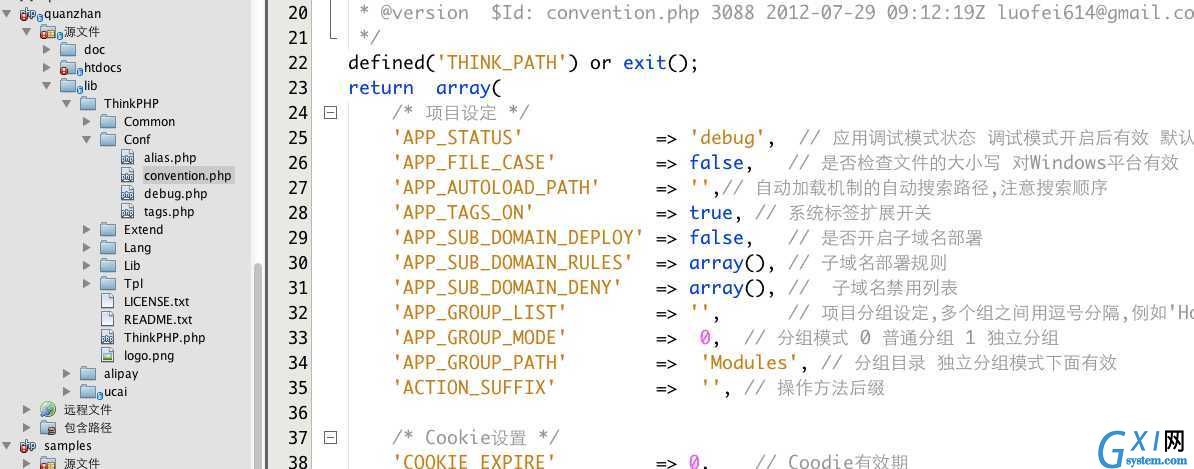
B、PHP保存配置数据就更加常见了,TP就是一个典型。
3.2、文本数据库(php text db api)
我们从 http://www.c-worker.ch/txtdbapi/index.php#download 下载了这个比较有名的 文本数据库引擎。
文本数据的使用场景这些交待一下。
1、比如你的虚拟主机,支持PHP,但是不支持MySQL ,也不支持SQLite的时候就可以发挥用场了。
下载了需要修改一下,
txt-db-api.php 的两个配置。
?
$API_HOME_DIR=dirname(__FILE__).DIRECTORY_SEPARATOR;
$DB_DIR=dirname(__FILE__).DIRECTORY_SEPARATOR; |
通过 http://samples.app.ucai.cn/20140603/phptxtdb/examples/addressbook.php?lang=de&char=M
就可以看到这个文本数据库的运行的例子。
然后就可以看到结果保存了。
果真是文本不是?
3.3、SQLite 数据库
SQLite 数据库也是一个文件数据库,但是不是文本数据库。它是一种自有的二进制格式。最早是由C写的一个库,并且很早也发布PHP的访问扩展,现在一般用的是sqlite3,PHP模块名也叫sqlite3。
Sqlite 有两个特点:
1、目前已经是非常流行的文件数据库,尤其是嵌入式数据库,在移动应用中也应用得十分普遍。
2、其访问的接口同 MySQL的非常地相似。
具体安装很简单,就是从官网下了代码, make 就可以了,不过代码可真不是一个小个。
3、SQLite3 已经是属于关系数据库大家庭的一员,所以它遵循ACID。对于SQL语句的支持也不错,网上也有人写了它和SQL互相导入互出的代码。
也有同MySQL 类似的管理工具,
http://sourceforge.net/projects/sqlitemanager/
大家可以搜索SQLite Manager 就能搜索到一堆。
至于具体的操作,不在这里展开,我们五月份的公开课,专门有一讲讲这个。将会比较详细地讲解SQLite 以及应用。
3.4、MySQL 数据库
MySQL 从使用上讲,大家都比较熟悉了。但是值得注意的是,mysql_query 这样的方法在php 5.5 时过时。
我们这里做三个简单的例子。分别用即将废弃的 mysql 和 mysqli 以 PDO 来操作数据库。
第一个例子,是过程式地操作MySQL。用的是很普遍的数据库操作函数,也就是php mysql 扩展的函数。这些函数将在 5.5版中过时,所以我们要抓紧改变了。
?
<?php
/**
* 优才网公开课示例代码
*
* mysql 过程式操作MySQL的例子
*
* @author 伍星
* @see http://www.ucai.cn
*/
$conn
= mysql_connect("127.0.0.1", "samples", "ftly5qb");
if(!mysql_select_db("samples", $conn))
{
echo
mysql_error();
exit;
}
// 这应该由用户提供,下面是一个示例
$name
= ‘wxstars‘;
// 构造查询
// 这是执行 SQL 最好的方式
// 更多例子参见 mysql_real_escape_string()
$query
= sprintf("SELECT * FROM users
WHERE name=‘%s‘",
mysql_real_escape_string($name));
// 执行查询
$result
= mysql_query($query);
// 检查结果
// 下面显示了实际发送给 MySQL 的查询,以及出现的错误。这对调试很有帮助。
if (!$result) {
$message
= ‘Invalid query: ‘
. mysql_error() . "\n";
$message
.= ‘Whole query: ‘
. $query;
die($message);
}
// 结果的使用
// 尝试 print $result 并不会取出结果资源中的信息
// 所以必须至少使用其中一个 mysql 结果函数
// 参见 mysql_result(), mysql_fetch_array(), mysql_fetch_row() 等。
while ($row = mysql_fetch_assoc($result)) {
echo
$row[‘id‘]."\n";
echo
$row[‘name‘]."\n";
echo
$row[‘email‘]."\n";
}
// 释放关联结果集的资源
// 在脚本结束的时候会自动进行
mysql_free_result($result);
mysql_close($conn);
?> |
第二个例子是过程式和面向对象的myqli操作数据库的例子。
?
<?php
/**
* 优才网公开课示例代码
*
* mysqli 过程式操作MySQL的例子
*
* @author 伍星
* @see http://www.ucai.cn
*/
$mysqli
= mysqli_connect("127.0.0.1", "samples", "ftly5qb", "samples", 3306);
/* check connection */
if (!$mysqli)
{
printf("Connect failed: %s\n", mysqli_connect_error());
exit();
}
// 这应该由用户提供,下面是一个示例
$name
= ‘wxstars‘;
// 构造查询
// 这是执行 SQL 最好的方式
// 更多例子参见 mysql_real_escape_string()
$query
= sprintf("SELECT * FROM users WHERE name=‘%s‘", mysqli_escape_string($mysqli, $name));
echo
$query;
/* Select queries return a resultset */
if ($result = mysqli_query($mysqli, $query))
{
printf("Select returned %d rows.\n", mysqli_num_rows($result));
$row
= mysqli_fetch_assoc($result);
print_r($row);
/* free result set */
mysqli_free_result($result);
}
mysqli_close($mysqli);
?>
<?php
/**
* 优才网公开课示例代码
*
* mysqli 面向对象操作MySQL的例子
*
* @author 伍星
* @see http://www.ucai.cn
*/
$mysqli
= new mysqli("127.0.0.1", "samples", "ftly5qb", "samples");
/* check connection */
if ($mysqli->connect_errno) {
printf("Connect failed: %s\n", $mysqli->connect_error);
exit();
}
// 这应该由用户提供,下面是一个示例
$name
= ‘wxstars‘;
// 构造查询
// 这是执行 SQL 最好的方式
// 更多例子参见 mysql_real_escape_string()
$query
= sprintf("SELECT * FROM users WHERE name=‘%s‘",
$mysqli->real_escape_string($name));
echo
$query;
/* Select queries return a resultset */
if ($result = $mysqli->query($query)) {
printf("Select returned %d rows.\n", $result->num_rows);
$row
= $result->fetch_assoc();
print_r($row);
/* free result set */
$result->close();
}
$mysqli->close();
?>
<?php
/**
* 优才网公开课示例代码
*
* PDO 操作MySQL的例子
*
* @author 伍星
* @see http://www.ucai.cn
*/
/* * * mysql hostname ** */
$hostname
= ‘127.0.0.1‘;
/* * * mysql username ** */
$username
= ‘samples‘;
/* * * mysql password ** */
$password
= ‘ftly5qb‘;
try
{
$dbh
= new PDO("mysql:host=$hostname;dbname=samples", $username, $password);
/* * * echo a message saying we have connected ** */
echo
‘Connected to database‘."\n";
/* * * The SQL SELECT statement ** */
$sql
= "SELECT * FROM users";
foreach
($dbh->query($sql) as
$row)
{
print
$row[‘id‘] . ‘ - ‘
. $row[‘name‘] . ‘ - ‘
. $row[‘email‘] . "\n";
}
/* * * close the database connection ** */
$dbh
= null;
} catch
(PDOException $e)
{
echo
$e->getMessage();
}
?> |
总结,我们上面使用了三个不同的php 模块,一个是php mysql,一个是mysqli,一个是 pdo_mysql 三个模块来分别干同样的事情。如果你单独学习这三个库,会觉得比较枯燥,当你学到一定程度,融会贯通时,特别是对比学习时发现,你学习了其中一个,学习其他的也就并不难了。无非就是如下几步:
1、建立连接,在建立 连接时需要提交用户名,密码,主机,库名,端口等数据。
2、检测连接是否建立成功。
3、组装查询,注意不同的模块,对查询组装时的过滤方法也是不同的。
4、执行查询,获得结果句柄,而不是直接的数据。
5、通过非常相近的函数,从结果句柄中取得数据。
6、把数据放到结果句柄里输出。
7、在离开程序时,需要释放结果集资源。
8、在最后,需要关系开启的数据库连接。
3.5、MySQL KVDB的一个插件
为什么要用这个插件,并演示这个插件,有几个目的。
一,让大家知道MySQL和KVDB,这些软件之间,并没有明显的界限,像KVDB的出现,只是它的处理能力更强,而MySQL由于很多的限制,导致了在简单的场景下,处理能力并不如KVDB强。并不是说不能做。
二、其实有人,将MySQL进行改造,已达到了甚至超过 KVDB的一个高度。就是这个插件所做的,据说做到了 75万QPS。并且是生产中可以使用的了,一些发行版均将这个模块包含了进去。
http://yoshinorimatsunobu.blogspot.com/2010/10/using-mysql-as-nosql-story-for.html
三、也让大家了解一下MySQL插件的安装。进一步了解MySQL的强大 。
https://github.com/DeNA/HandlerSocket-Plugin-for-MySQL
wget https://github.com/DeNA/HandlerSocket-Plugin-for-MySQL/archive/master.zip -O HandlerSocket-Plugin-for-MySQL.zip
unzip HandlerSocket-Plugin-for-MySQL.zip
进去目录
?
cd HandlerSocket-Plugin-for-MySQL-master/
sh autogen.sh
./configure |
发现出错,要求连同mysql 的源码目录一起配置。
下载了一个5.5版的源码,配置
./configure --with-mysql-source=../MySQL/mysql-5.5.37/
发现出错。
?
checking mysql binary... yes: Using /usr/bin/mysql_config, version 5.1.73
configure: error: MySQL source version does not match MySQL binary version |
只好查看了一下版本,
[root@localhost HandlerSocket-Plugin-for-MySQL-master]# mysqladmin --version
mysqladmin Ver 8.42 Distrib 5.1.73, for redhat-linux-gnu on x86_64
发现是5.1.73 的版本
于是乎下了一个5.1.73 的源码。
成功配置,
./configure --with-mysql-source=../MySQL/mysql-5.1.73/
然后
make
make install
成功安装。下面再在mysql 中启用
mysql –uroot –p
执行 install plugin handlersocket soname ‘handlersocket.so‘; 安装插件。
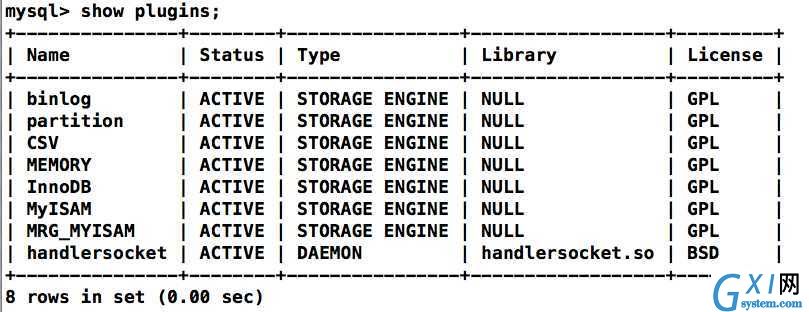
插件成功安装。
再在
?
/etc/my.cnf 的 [mysqld] 版块下加入
loose_handlersocket_port = 9998
loose_handlersocket_port_wr = 9999
loose_handlersocket_threads = 4
loose_handlersocket_threads_wr = 1
loose_handlersocket_address = [你要监听的IP地址] |
然后重启 mysqld
再show processlist

我们看到,已经成功运行,再netstat看一眼。
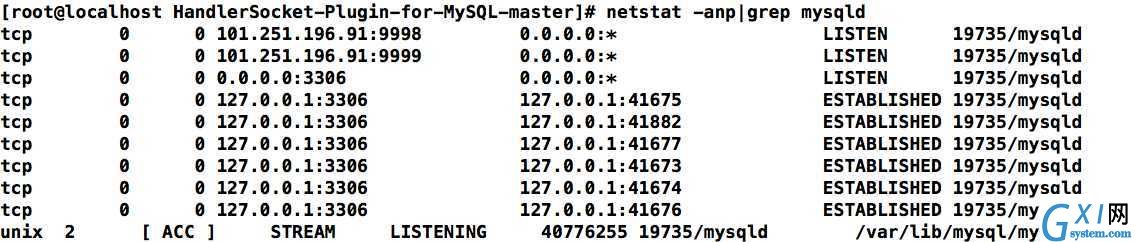
端口监听成功。
说明,此插件在MySQL的另一个发行版 Percona Server中已包含。
http://www.mysqlperformanceblog.com/2010/12/14/percona-server-now-both-sql-and-nosql/
我们来使用它的 PHP 客户端来测试一下。
下载:
https://code.google.com/p/php-handlersocket/downloads/detail?name=php-handlersocket-0.3.1.tar.gz&can=2&q=
安装模块。
新建测试代码。
新建表格
create database hstestdb;
?
CREATE TABLE `hstesttbl` (
`k` int(11) NOT NULL AUTO_INCREMENT,
`v` char(255) NOT NULL DEFAULT ‘‘,
PRIMARY KEY (`k`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
<?php
$host
= ‘101.251.196.91‘;
$port
= 9998;
$port_wr
= 9999;
$dbname
= ‘hstestdb‘;
$table
= ‘hstesttbl‘;
//GET
$hs = new HandlerSocket($host, $port);
if (!($hs->openIndex(1, $dbname, $table, HandlerSocket::PRIMARY, ‘k,v‘)))
{
echo
$hs->getError(), PHP_EOL;
echo
"get Error!\n";
die();
}
$retval
= $hs->executeSingle(1, ‘=‘, array(‘k1‘), 1, 0);
var_dump($retval);
$retval
= $hs->executeMulti(
array(array(1, ‘=‘, array(‘k1‘), 1, 0),
array(1, ‘=‘, array(‘k2‘), 1, 0)));
var_dump($retval);
unset($hs);
//UPDATE
$hs = new HandlerSocket($host, $port_wr);
if (!($hs->openIndex(2, $dbname, $table, ‘‘, ‘v‘)))
{
echo
$hs->getError(), PHP_EOL;
die();
}
if ($hs->executeUpdate(2, ‘=‘, array(‘k1‘), array(‘V1‘), 1, 0) === false)
{
echo
$hs->getError(), PHP_EOL;
die();
}
unset($hs);
//INSERT
$hs
= new HandlerSocket($host, $port_wr);
if (!($hs->openIndex(3, $dbname, $table, ‘‘, ‘k,v‘)))
{
echo
$hs->getError(), PHP_EOL;
die();
}
if ($hs->executeInsert(3, array(‘k2‘, ‘v2‘)) === false)
{
echo
$hs->getError(), PHP_EOL;
}
if ($hs->executeInsert(3, array(‘k3‘, ‘v3‘)) === false)
{
echo
‘A‘, $hs->getError(), PHP_EOL;
}
if ($hs->executeInsert(3, array(‘k4‘, ‘v4‘)) === false)
{
echo
‘B‘, $hs->getError(), PHP_EOL;
}
unset($hs);
//DELETE
$hs
= new HandlerSocket($host, $port_wr);
if (!($hs->openIndex(4, $dbname, $table, ‘‘, ‘‘)))
{
echo
$hs->getError(), PHP_EOL;
die();
}
if ($hs->executeDelete(4, ‘=‘, array(‘k2‘)) === false)
{
echo
$hs->getError(), PHP_EOL;
die();
} |
3.6、全文检索
全文检索是不一个不同于数据检索的领域。有几个特点:
A、精确的数据库查询,无论是在顺序,还是在数据结构上都是非常地确定的。
B、全文检索一般面向大数据量,所以查询结果,在顺序上和结果上,都不是需要达到 100%精确,当然也有一些技术指标来衡量向着最好的方向前进。
C、精确查询所查询的内容,一般是数字型的比较或者是前置匹配等。
D、全文检索所查的内容,往往是一段文字中的一个或者多个词。所以只查文本型的数据。
E、精确查询往往随着数据量的记录数到了一定程度,如果是针对文本的查询,整个速度会下降比较明显。
F、而全文检索一



























