SQL Server - 聚集索引 <第六篇>
时间:2022-03-15 05:15
聚集索引的叶子页存储的就是表的数据。因此,表行物理上按照聚集索引列排序,因为表数据只能有一种物理顺序,所以一个表只能有一个聚集索引。
当我们创建主键约束时,如果不存在聚集索引并且该索引没有被明确指定为非聚集索引,SQL Server会自动将其创建为唯一的聚集索引,这并不是说主键列就一定是聚集索引,这只是默认行为而已。
示例,建表时通过指定主键为非聚集索引使主键列不为聚集列:
CREATE TABLE MyTableKeyExample
{
Column1 int IDENTITY PRIMARY KEY NONCLUSTERED,
Column2 int
}
在有聚集索引的情况下,检索范围排序的数据:
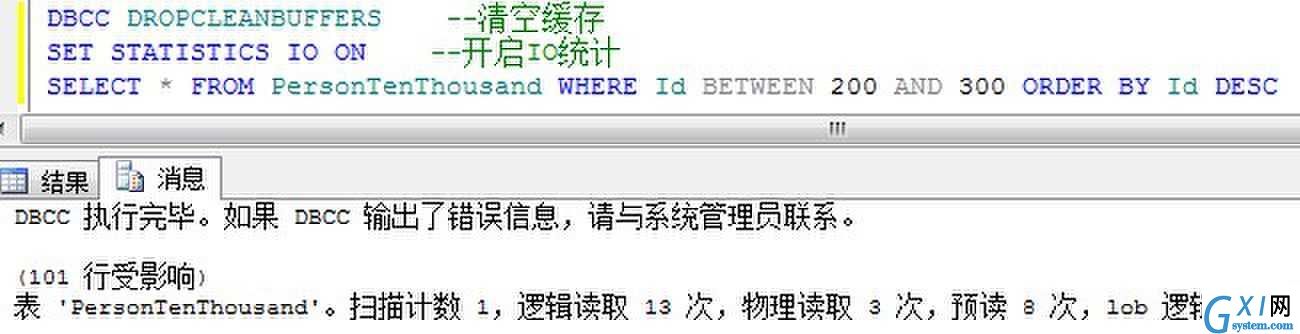
从中看到,有聚集索引的范围排序返回数据非常快速,因为对于聚集列,本身就是已经排好顺序存放于数据库中的。
5、何时不使用聚集索引
在某些情况下,最好不使用聚集索引。
1、频繁更新的列
如果聚集索引列频繁更新,将导致所有非聚集索引行的行定位器相应更新,从而显著地增加相关操作查询的开销。还将阻塞这段时间引用相同部分和非聚集索引的其他查询,从而影响数据库的并行性。因此,应该避免在大量更新的列上创建聚集索引。
2、宽的关键字
因为所有非聚集索引将聚集键作为其行定位器,所以为了性能,应该避免在非常宽或太多列上创建聚集索引。上面红色加粗字体特别说明了原因。
3、太多并行的顺序插入
如果希望并发地添加许多新行,那么对于性能来讲,将他们分布到表的各个数据页面更好一些。但是,如果将所有行按照与聚集索引相同的顺序添加,那么所有的插入操作都在表的最后一个页面上进行。这可能在磁盘的对应山区造成一个巨大的“热点”,为了避免磁盘热点,不应该将数据行按照物理位置相同的顺序排列。可以通过创建另一列上的索引(该索引不会将行按照新航相同的顺序来排列)来插入操作随机地分布到整个表。这个问题只在大量同时插入时发生。
允许在表的尾部插入,能够避免需要容纳新行时发生的页拆分。如果并行插入数据降低,那么按照新行的顺序来排列数据行(使用聚集索引)将避免页拆分。但是,如果磁盘热点成为性能瓶颈,那么新行可以通过降低表的填充因子来容纳到中间页面。另外,“热”的页面将在内存中,这也有利于性能。
最后附上一个设置非主键为聚集索引列的方法:
1. 查看所有的索引,默认情况下主键上都会建立聚集索引
查看索引:
sp_helpindex person
查看约束:
sp_helpconstraint person
2. --删除主键约束,把【1】中查询出的主键上的索引约束【如:PK__person__117F9D94】去除掉。去掉主键字段上面的主键约束,此时该字段不是主键了。
alter table person drop constraint PK_Person
3.--创建聚集索引到其它列
create clustered index test_index on person(Name)
4.—修改原来的主键字段还是为主键,此时会自动建立非聚集索引【因为已经有了聚集索引】
sp_helpindex person
sp_helpconstraint person
alter table person drop constraint PK_Person
create clustered index test_index on person(Name)
alter table person add primary key (id)
相关推荐
- xshell怎么连接数据库
- MySQL数据库设计规范(仅供参考)
- SQLServer字符串查找(判断字符串是否含数字或字母)
- MySQL源码安装5.7-CentOS7
- 数据库常用架构和同步工作原理
- Apache HBase 1.7.1 发布,分布式数据库
- SQL Server 数据库分离和附加
- sqlSugar 简单封装及使用案例
- 【MySQL】-索引类型
- mysql的数据类型详解
电脑软件
热门排行
今日推荐
热门手游
-
我的水晶花园官方版

版本:v2.7.7
大小:88.83MB
日期:2024-09-25
-
平民小富商正版

版本:v1.0.1
大小:53.92MB
日期:2024-09-25
-
闲置农场生活安卓版

版本:v1.0.0
大小:39.36MB
日期:2024-09-25
-
凯蒂猫超市小镇手机版

版本:v1.0
大小:264.07MB
日期:2024-09-25
-
小偷模拟器2正版

版本:v1.0.0
大小:94.96MB
日期:2024-09-25
-
2024巴黎奥运会手机版

版本:v1.5.0
大小:1MB
日期:2024-09-25
sp_helpindex person
查看约束:
sp_helpconstraint person
alter table person drop constraint PK_Person
相关推荐
- xshell怎么连接数据库
- MySQL数据库设计规范(仅供参考)
- SQLServer字符串查找(判断字符串是否含数字或字母)
- MySQL源码安装5.7-CentOS7
- 数据库常用架构和同步工作原理
- Apache HBase 1.7.1 发布,分布式数据库
- SQL Server 数据库分离和附加
- sqlSugar 简单封装及使用案例
- 【MySQL】-索引类型
- mysql的数据类型详解
电脑软件
















热门排行
今日推荐






热门手游
-
我的水晶花园官方版
版本:v2.7.7
大小:88.83MB
日期:2024-09-25
-
平民小富商正版
版本:v1.0.1
大小:53.92MB
日期:2024-09-25
-
闲置农场生活安卓版
版本:v1.0.0
大小:39.36MB
日期:2024-09-25
-
凯蒂猫超市小镇手机版
版本:v1.0
大小:264.07MB
日期:2024-09-25
-
小偷模拟器2正版
版本:v1.0.0
大小:94.96MB
日期:2024-09-25
-
2024巴黎奥运会手机版
版本:v1.5.0
大小:1MB
日期:2024-09-25