SQL Server 索引 之 书签查找 <第十一篇>
时间:2022-03-15 05:15
注意到以上数据是无序的。
上面建立的非聚集索引因为使用了RID作为书签,直接指向对应行所在的物理位置,因此效率不错。虽然RID值用于键查找非常高效,但书签中包含的值与具体的用户数据无关。
2、在聚集索引上的非聚集索引:基于聚集键的书签
如果表示基于聚集索引的,则表内数据可以在表移动。因此,对于聚集索引来说,RID并不能一直不变的定位一个相同的行。因此必须用另外的方法定位行,这个方法就是使用聚集索引的索引键。
使用聚集索引键作为书签可以使得当数据在页中的行改变时,不需要非聚集索引的书签的值进行变动,因此非聚集索引的键就可以用于去找底层表的数据,即根据书签取数据不再基于物理位置,而是基于聚集索引查找。
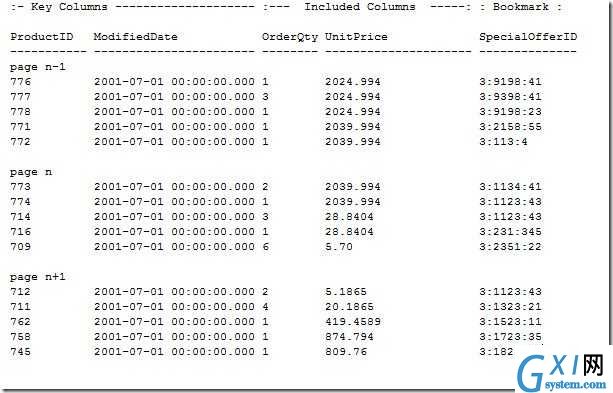
以聚集索引键作为非聚集索引的书签最好要聚集索引键满足如下标准:
索引应该具有唯一性:每一个索引条目书签都应该使得书签可以通过聚集索引的键值唯一的确认表中的一行,如果你创建的聚集索引键值不唯一,SQL Server将会为有重复键值的每一行自动加上一个叫uniquifier的东西使得每一行唯一。这个uniquifier对客户端是透明的。对于是否可以允许聚集索引键重复,要考虑以下两点:
- 生成uniquifier增加SQL Server插入操作的额外负担,在插入时SQL Server还需要判断插入的值在表中是否唯一,如果不唯一生成uniquifier值再进行插入。
- uniquifier本身对业务数据来说是没有意义的,但是这个uniquifier本身不仅仅需要占用聚集索引键的空间,还同时占用非聚集索引书签的空间
索引键应该短:索引键所占的字节数应该短.因为这个键还会占用非聚集索引书签的空间。比如Contact表中以Last name / first name / middle name / street组合作为索引键看上去不错,但如果表中存在多个非聚集索引的话情况就有些微妙了。n个非聚集索引使得Last name / first name / middle name / street这些字段被存储在n+1个位置。
索引键最好不要变动:也就是索引键的值最好不要变动。对于聚集索引键的修改会使得基于这个聚集索引的所有非聚集索引同样进行修改。所以对于聚集索引的一次update会造成n个非聚集索引书签的update+1个聚集索引键值本身的update。
下面以一个示例来帮助理解书签查找:
假设数据库有一张表如下:
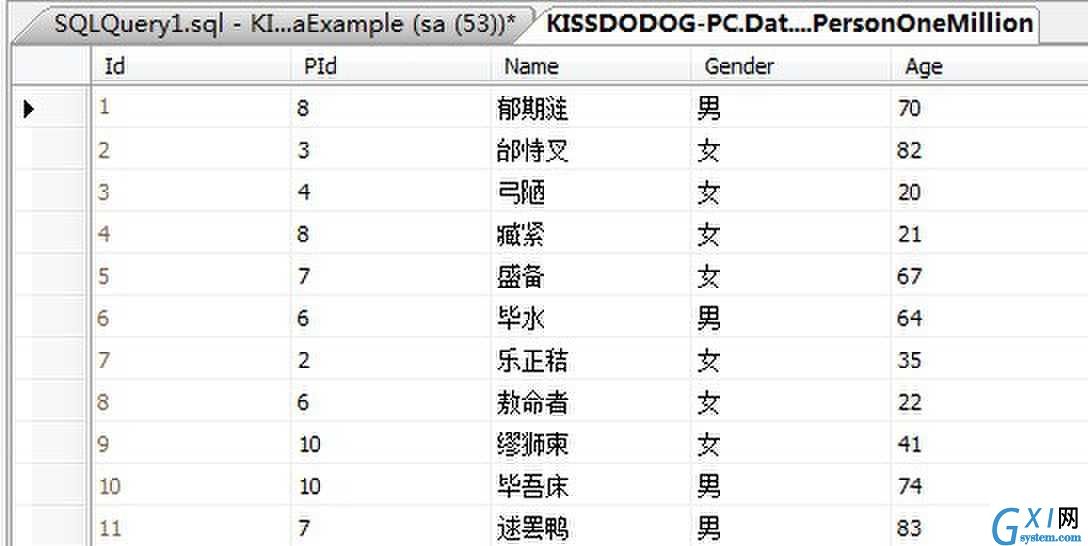
我们再Name列建一个非聚集索引,然后执行下面的语句:
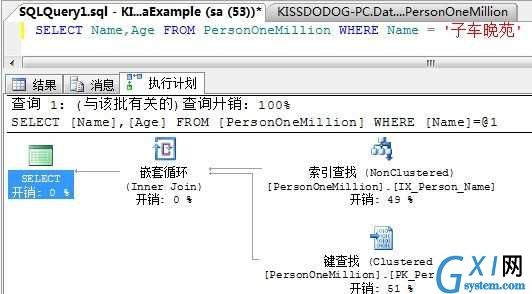
从执行计划我们可以看到,因为Age列并不在非聚集索引中,所以SQL Server通过“键查找”引导到聚集表获取数据,这就是书签查找。
书签查找的目的,就是为了从非聚集索引导航到基本表获取非聚集索引中并未包含的信息。
返回300条:
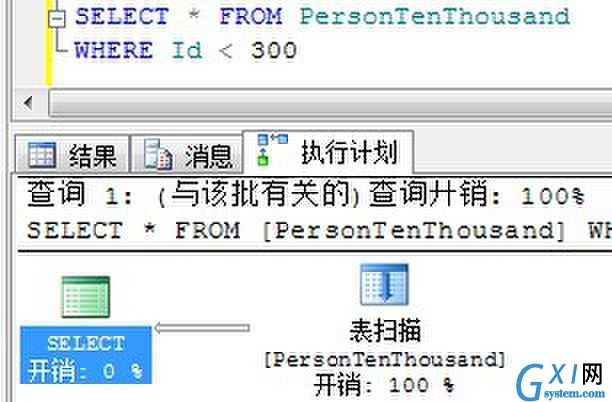
我们看到,当要求返回300条数据的时候,SQL Server就不在使用Id列上的非聚集索引,而是直接进行表扫描了。因为SQL Server认为执行300次书签查找还不如直接对一张1万条记录的表进行全表扫描。
由上面的实例可以得出结论,返回大的结果集将增加书签查找的开销,甚至低于表扫描。因此在返回较大结果集的情况下,必须考虑避免书签查找的可能性。
下面修改索引增加Name列。
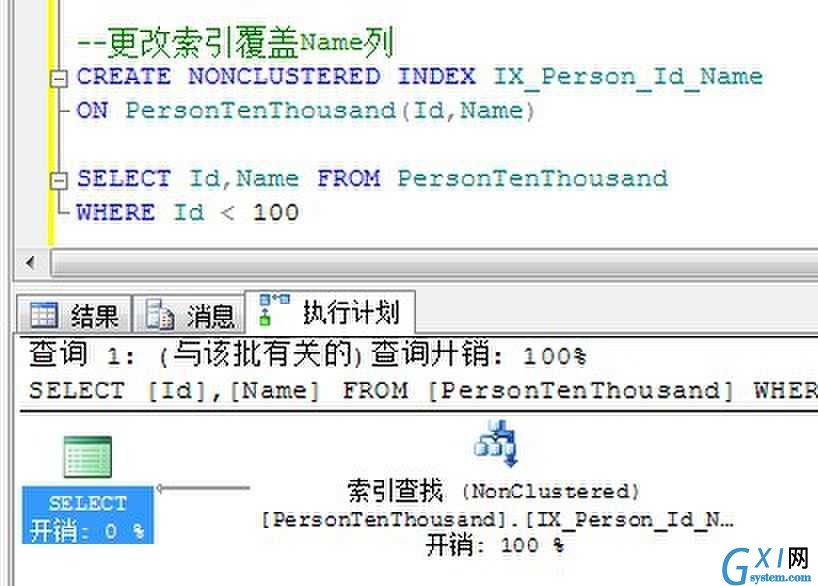
由于非聚集索引上已经有了需要查询的Id和Name列的数据,所以不在需要书签查找定位到基本表。
3、使用索引连接
如果覆盖索引变得非常宽,那么可能要考虑索引连接技术。索引连接技术使用两个或更多索引之间的一个索引交叉来完全覆盖一个查询。因为索引连接技术需要访问多余一个索引,它必须在所有索引连接中使用的索引上执行逻辑读。因此,索引连接需要比覆盖索引更高的逻辑读数量。但是,因为索引连接所用的多个窄索引能够比宽的覆盖索引服务更多的查询。所以索引连接也可以作为避免书签查找的一种技术来考虑。
我们来看下面的实例:
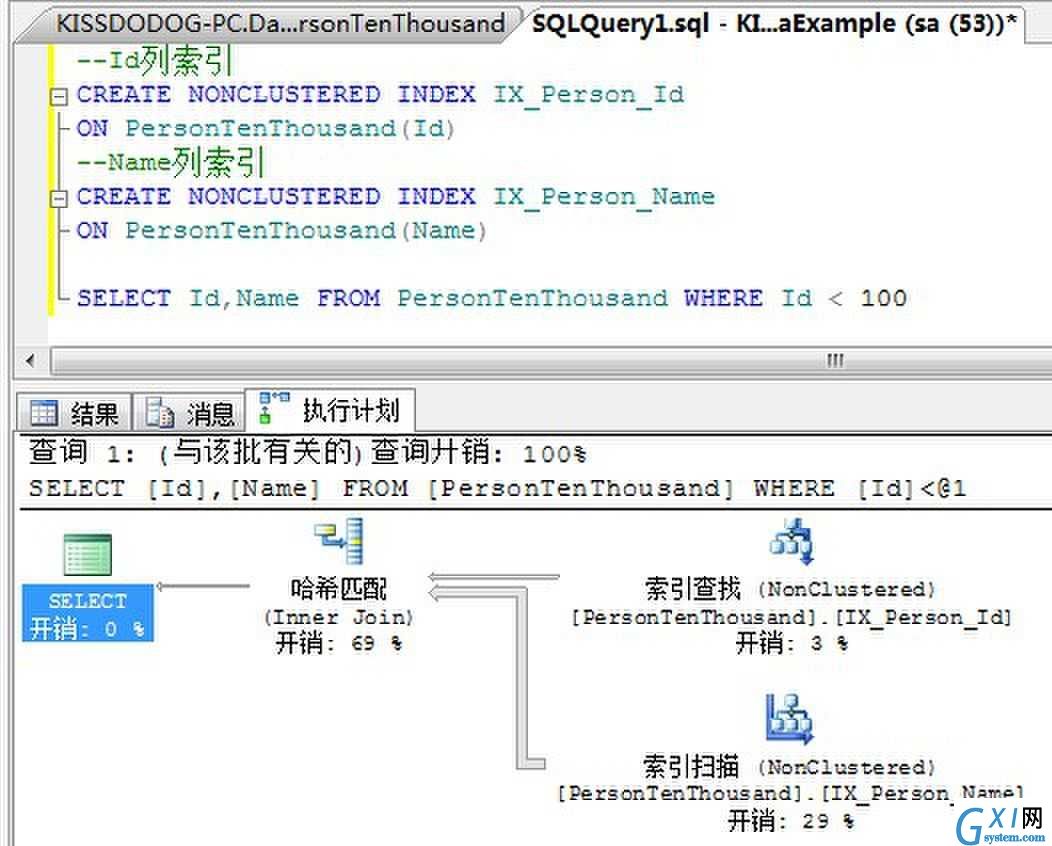
留意到,上面的例子我们创建了两个非聚集索引,一个在 Id列,一个在Name列。但是我们的查询需要同时返回Id列和Name列。而这两个非聚集索引都不完全包含要返回列。这个时候,哈希匹配目的就是通过定位到索引,而不用定位到基本表就能够获得我们所需要的全部数据,这样索引连接就避免了书签查找。
















热门排行
今日推荐






热门手游
-
我的水晶花园官方版

版本:v2.7.7
大小:88.83MB
日期:2024-09-25
-
平民小富商正版

版本:v1.0.1
大小:53.92MB
日期:2024-09-25
-
闲置农场生活安卓版

版本:v1.0.0
大小:39.36MB
日期:2024-09-25
-
凯蒂猫超市小镇手机版

版本:v1.0
大小:264.07MB
日期:2024-09-25
-
小偷模拟器2正版

版本:v1.0.0
大小:94.96MB
日期:2024-09-25
-
2024巴黎奥运会手机版

版本:v1.5.0
大小:1MB
日期:2024-09-25