MySql的基本操作以及以后开发经常使用的常用指令
时间:2022-03-15 01:26
第一章:数据类型和操作数据表
语句的规范
(1):关键字与函数名称全部大写
(2):名称,表名称,字段名称全部小写
(3):SQL语句必须以分号结尾
1:命令行模式启动mysql服务
net start mysql
2:命令行模式关闭mysql服务
net stop mysql
3:mysql退出
mysql>exit;
mysql>quit;
mysql>\q;
4:显示当前服务器版本
select version();
5:显示当前日期时间
select now();
6:显示当前用户
select user();
7:创建数据库
CREATE DATABASE 数据库名;

8:查看当前服务器下的数据表列表
SHOW DATABASES;
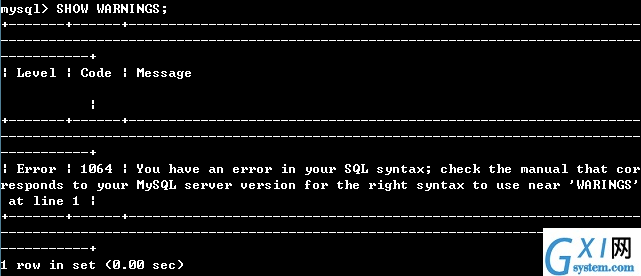
9:查看警告信息
SHOW WARNINGS;

10:显示数据库创建的时候显示的指令是多少
SHOW CREATE DATABASE 数据库名;
11:指定数据库的编码方式
CREATE DATABASE IF NOT EXISTS 数据库名 CHARACTER SET gbk;

12:修改数据库
13:修改数据库的编码方式
ALTER DATABASE 数据库名 CHARACTER SET = UTF8;

14:删除数据库
DROP DATABASE 数据库名;
15:登录mysql客户端数据库
mysql -u账户 -p密码 -P端口号 -hip地址
16:打开数据库
(连贯操作
第一SHOW DATABASES;
第二USE 数据库名
第三SHOW TABLES;
)
USE test;


17:(显示当前用户打开的数据库)
SELECT DATABASE();
18:创建数据表(UNSIGNED不可以为负)
CREATE TABLE [IF NOT EXISTS] 数据表名(
数据表列名称 数据类型,
username VARCHAR(20),
age TINYINT UNSIGNED,
salary FLOAT(8,2) UNSIGNED
);
19:查看数据表
SHOW TABLES;
SHOW TABLES FROM mysql;//查看mysql的数据表
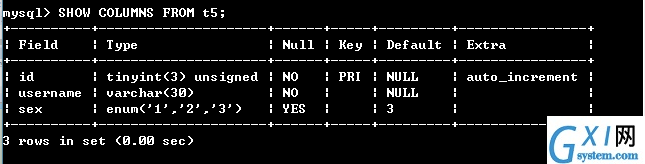
20:查看数据表结构
SHOW COLUMNS FROM 数据表的名称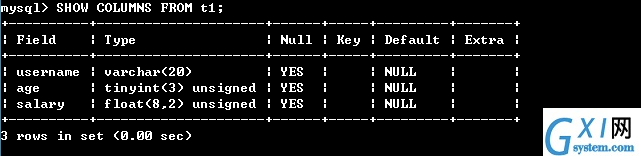
21:向数据表中写入记录,插入记录
INSERT [INTO] 表的名字[(col_name,...)] 值(val,...)
INSERT t1 VALUES(‘TOM‘,22,8000.25);


22:记录的查找命令SELECT(查看表里面的内容)
记录查找
SELECT * FROM t1;
23:空值和非空值
NULL:字段值可以为空
NOT NULL:字段值禁止为空

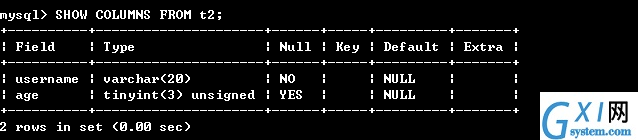


查看表的结构DESC 表名;


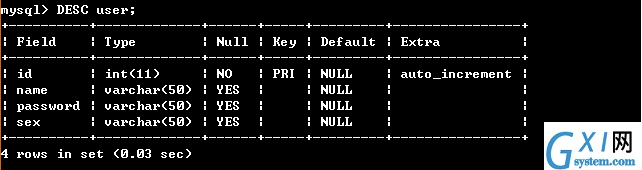
24:自动编号
AUTO_INCREMENT
自动编号,且必须与主键组合使用
默认情况下,起始值为1,每次的增量为1;
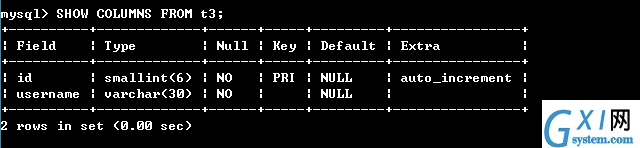
25:主键PRIMARY KEY(primary key)
主键约束
每张数据表只能存在一个主键
主键保证记录的唯一性
主键自动为NOT NULL;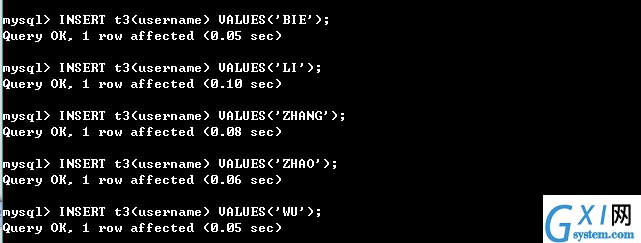

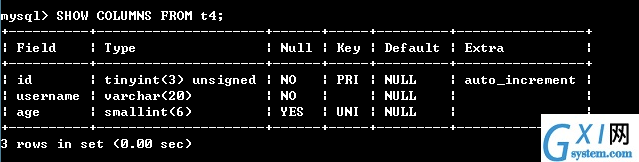
26:唯一约束UNIQUE KEY
唯一约束
唯一约束可以保证记录的唯一性
唯一约束的字段可以为空值
每张数据表可以存在多个唯一约束
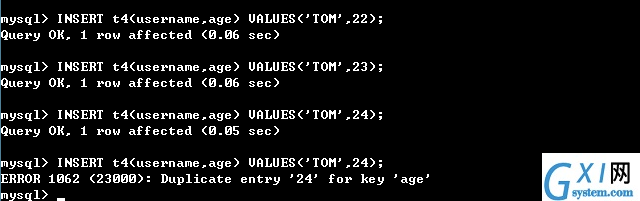
27:默认约束DEFAULT
默认值
当插入记录时,如果没有明确为字段赋值,则自动赋予默认值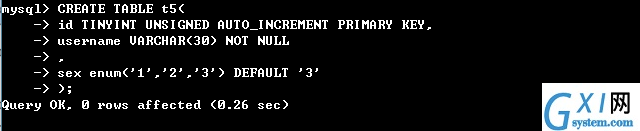


扩展,修改表的名字
1:下面详细的说一下以后经常使用的命令和操作,方便大家学习和自我脑补
(首先打开mysql自带的命令行输入密码即可登录,必须保证mysql的服务启动起来,不然输入密码按enter键会闪退,如何起服务请自行脑补)
2:(登录以后首先查看自己的mysql的数据库,mysql自带四个数据库,其他是自己创建的)

3:(做项目首先就是先创建一个数据库,如下图所示,CREATE DATABASE 数据库名,我强烈建议mysql语句大写,以示区别,纯属个人建议与习惯,最后的分号一定要加上,切记)

4:(创建好数据库可以查询一下使用SHOW DATABSES;命令,切记DATABASES后面又一个s,后面加分号;结束按enter键查询即可)

5:(删除创建好的数据库,命令是DROP DATABASE 数据库名;切记加分号;)

6:(再次查询自己的数据库显示已经删除了)

7:(在此我使用以前创建的数据库demo,查看数据库以后就可以使用USE 数据库名;切换到某一个数据库,然后操作这个数据库里面的数据表)

8:(显示这个数据库里面的数据表,SHOW TABLES;显示这个数据库里面的数据表,这是以前创建的数据表)

9:(显示后发现没有自己想要的,就自行创建一个数据表,命令CREATE TABLE 数据表名(字段名 字段的数据类型,。。。。); 需要注意的就是最后);后面的分号,一定要加上去,格式如下图所示,创建一个最简单的数据表。 )

10:(创建好数据表查看创建好的数据表,命令上面已经说过,不作多叙述)

11:(当创建的数据表不符合自己的需求时删除即可,命令如下,DROP TABLE 数据表名; 即可删除创建好的数据表)

12:(创建命令上面说过,不作多叙述,这里加入了mysql的约束,在id加上了主键PRIMARY KEY和自动增加AUTO_INCREMENT这两个约束,需要注意的就是主键和自动增加的单词别拼写错误了,不然命令就会报错)

13:(再次查看自己创建好的数据表)

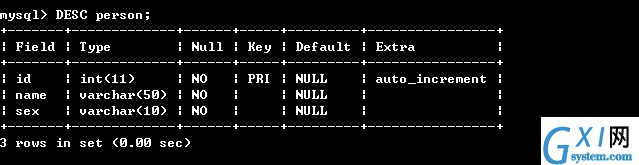
14:(查看自己创建好的数据表的结构,下面显示了字段名称,字段的类型,字段是否为空,是否为主键,和是否自动增加等等)
15:(创建数据表的目的就是使用它,下面就是插入一条语句,命令INSERT INTO 数据表名 VALUES(字段的值); 字段的值需要注意的是:当添加的字段的数据类型是int类型,直接写值,如果添加的字段的类型是varchar类型和日期类型,使用单引号把值包起来,格式如下图所示即可。)
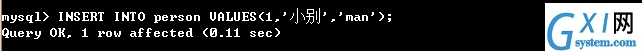
16:(插入完成后就可以查看自己的数据表里面是否插入成功,命令SELECT * FROM 数据表名;)

17:(插入的方式除了上面那种还可以使用下面这种,由于id是自动增加的,所以id那个字段可以省略,其他字段的添加内容即可,需要注意的是数据表名(字段名) 和values(字段值),必须一 一对应,格式如下所示。)
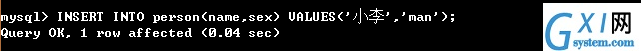
18:(然后再次查看数据表里面的内容即可)

19:(更新操作,命令UPDATE 数据表明 SET 更新的内容 WHERE 更新的条件)

20:(更新操作完毕后查看是否更新完成)

21:(删除命令,如下所示,DELETE FROM 数据表名 WHERE 删除的条件,或者直接DELETE FROM 数据表名,即把这个数据表全部删除,这里不做演示,请自行脑补)
22:(然后查看自己的数据表即可,已经完成删除了)

23:(查询的方式上图已经说了,如SELECT * FROM 数据表名;请自行脑补,下面说一下其他的查询方式,只查询部分内容,SELECT 查询的字段 FROM 数据表名;如下图)

24:(带有条件的查询语句,如下图,SELECT * FROM 数据表名 WHERE 查询条件)

25:(查询的时候也可以起别名,下面给字段起别名,命令SELECT 字段名 AS 别名,... FROM 数据表名)
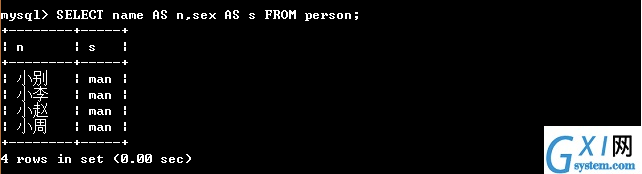
26:(查询的时候也可以起别名,下面给字段起别名,命令SELECT 字段名 别名,... FROM 数据表名,需要注意的是也可以将AS省去也可)

27:(也可以将数据表名起别名,格式如下,请自行脑补)
28:(distinct,去除表里面重复语句查询;记录语句 select distinct * from 表名;)由于我的数据表里面的id设置为主键了,无法添加重复的值,在此不做演示。请自行脑补。。。。。。
29:(第一,运算符 < > >= <= WHERE的条件查询需要多做练习,如下图所示,请自行脑补WHERE 后面是条件)
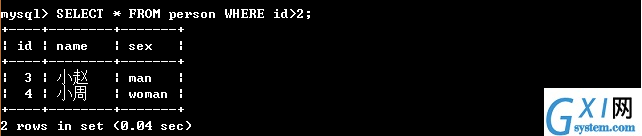
30:(in:在范围内 代表在范围内的,如下图所示)

31:(in后面也可以加多个查询值)
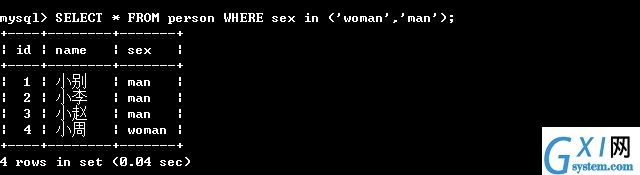
32:(第三,and:在where里面如果有多个条件,表示多个条件同时满足)
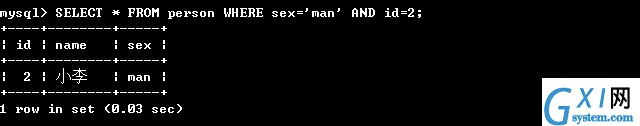
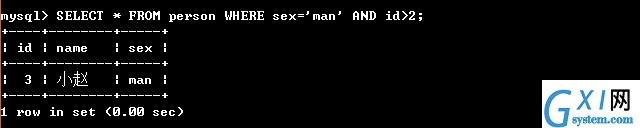
33:(第三,and:在where里面如果有多个条件,表示多个条件同时满足,可以是范围也可以是具体的)
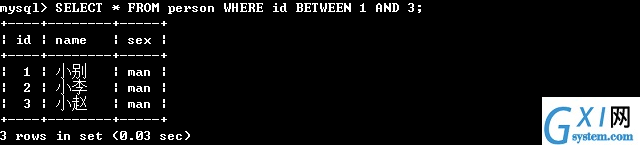
34:(第四,得到区间范围的值,注意使用AND 和BETWEEN ... AND的区别,容易出错)
35:(第五,like:模糊查询 ; _下划线代表一个字母,%代表多个字母)

36:(查询当前的时间)

37:(注意:order by写在select语句的最后 ;降序 order by 要排序字段 desc)

38:(第一,升序 order by 要排序字段 asc(asc可以省略,默认的情况下就是升序))

39:(排序ORDER BY需要写在最后面,前面可以加条件控制筛选后进行排序升序或者降序)
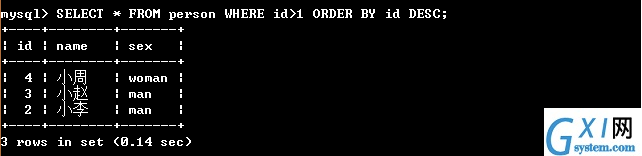
40:聚集函数的使用
(count()函数,根据查询的结果,统计记录数,写法 select count(*) from ...where....)

41:(还可以为count(*)起别名,如下图所示)

42:(还可以使用WHERE进行筛选条件统计查询)
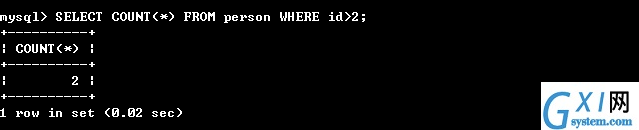
43:(sum()函数,求和的函数,写法 select sum(要进行求和字段) from ...where....)

44:(下图也是求平均数和45的AVG函数做对比)
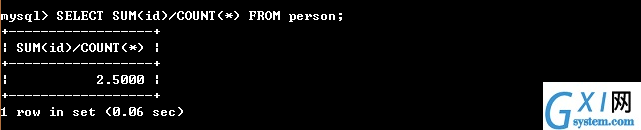
45:(avg()函数,计算的平均数的函数,写法 select avg(要计算平均数的字段名称) from ...)

46:(max()函数:计算最大值,写法 select max(字段) from...)

47:(min()函数:计算最小值,写法 select min(字段) from...)

48:(分组使用 group by 根据分组的字段 WHERE子句里面不能写具体函数,写了就报错,我在这里已经重新创建新的数据表,请自行脑补)
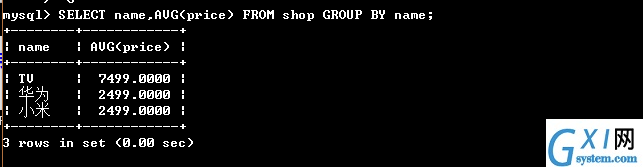

49:(在分组的基础之上再进行条件的判断 having,后面可以写聚集函数,因为使用WHERE后面无法使用具体的聚集函数,所以使用HAVING后面加聚集函数进行使用)

(上下两张图做对比,先分类name然后把一样类求总和)
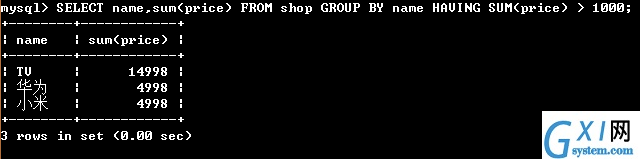
50:分页查询,LIMIT 0,5;执行分页查询,第一个数字代表从那个开始,第二个数字代表一页有几个。

举两个例子,上下如图
51:多表查询,(笛卡尔乘积);连接查询(是将两种或者两种以上的表按照某种条件连接起来,从中选取需要的数据)
(后面介绍一下:内连接查询,外连接查询,左连接查询,右连接查询,多条件连接查询)
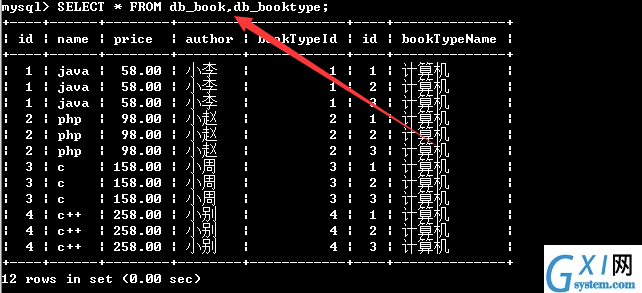
52:内连接查询:(是一种常见的连接查询,内链接查询可以查看两个多两个以上的表)需要注意的是‘’去掉也可以执行的。也可以查询详细字段,将详细字段替换掉*即可。不过这样写有缺陷,不知道查询的是那个表里面的。
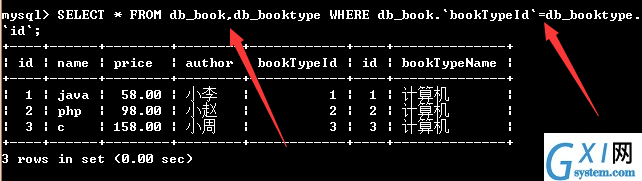
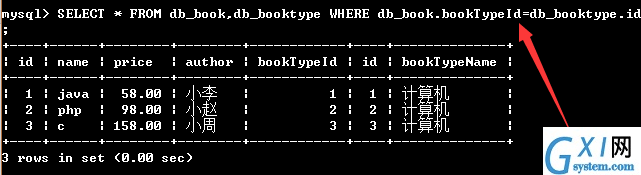
53:外连接:外连接包含左连接和右连接,如下(可以查询一个表的所有信息)
54:左连接查询:(可以查询出表名1 的所有记录,而表名2中只能查出匹配的记录)
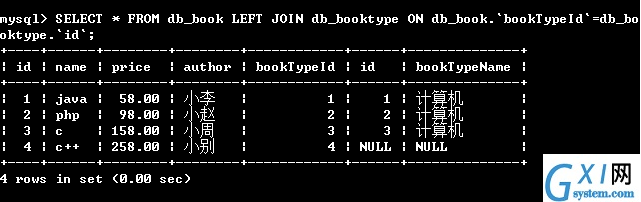
左连接别名查询,以后开发可能会经常这样使用,起别名,可以省去AS。
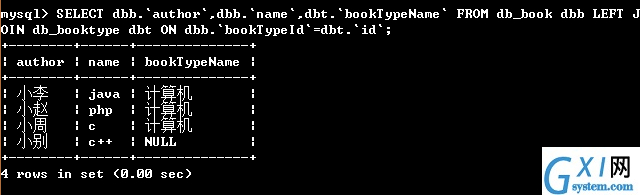
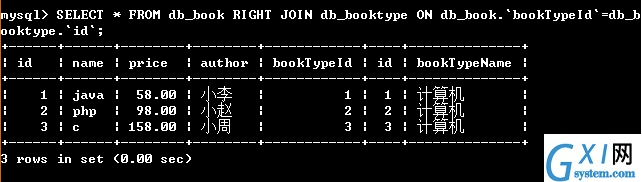
55:右连接查询:(可以查询出表名2 的所有记录,而表名1中只能查出匹配的记录);右连接别名查询省去没写,请自行脑补。
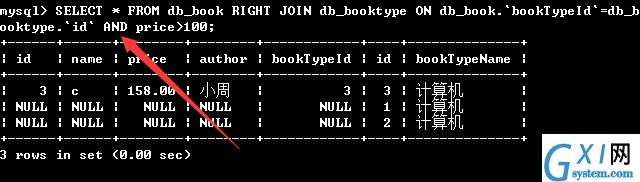
56:多条件查询,其实就是后面使用AND连接一下,进行多条件查询即可。
57:子查询
58:带IN关键字的子查询
一个查询语句的条件可能落在另一个SELECT语句的查询结果中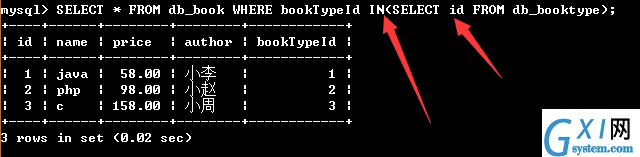
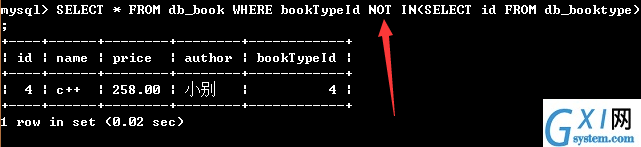
(带NOT IN关键字的子查询)
59:带有比较运算符的子查询
子查询可以使用比较运算符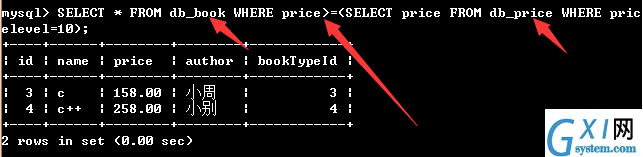
60:带有EXISTS关键字的子查询
假如子查询查询到记录,其实就是判断一下内层为ture,则进行外层查询,如果为false,不执行外层查询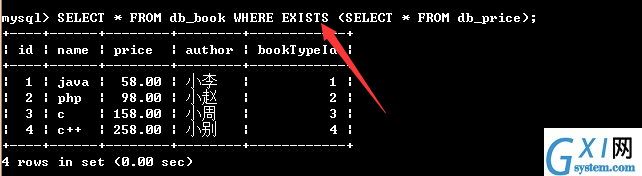
带有NOT EXISTS关键字的子查询

61:带ANY关键字的子查询
ANY关键字表示满足其中任一条件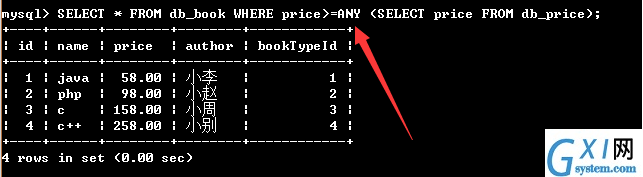
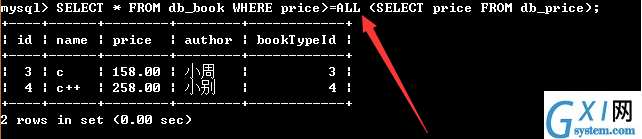
62:带ALL关键字的子查询
ALL关键字表示满足所有条件
63:合并查询结果
64:UNION , 使用UNION关键字是,数据库系统会将所有的查询合并到一起,然后去除掉相同的记录
65:UNION ALL ,使用UNION ALL,不会去除掉系统重复的记录
66:索引引入
索引定义:索引是由数据库表中一列或者多列组合而成,其作用是提高对表中数据的查询速度,类似于图书的目录,方便快速定位,寻找指定的内容
索引的优缺点:
优点:提高查询数据的速度
缺点:创建和维护索引的时间增加了。
67:索引分为普通索引
这类索引可以创建在任何数据类型中
68:唯一索引
使用UNIQUE参数可以设置,在创建唯一索引时,限制该索引的值必须时唯一的
(唯一索引,起别名,在index后面加上自己取的别名即可。)

69:全文索引(由于不支持,咱不演示)
使用FULLTEXT参数可以设置,全文索引只能创建在CHAR,VARCHAR,TEXT类型的字段上。主要作用就是提高查询较大字符串类型的速度,只有MYISAM引擎支持该索引,mysql默认引擎不支持
70:单列索引(上面写的两种都是单列索引,不多叙述)
在表中可以给单个字段创建索引,单列索引可以时普通索引,也可以是唯一索引,还可以时全文索引
71:多列索引
多列索引在表的多个字段上创建一个索引
72:空间索引(由于不支持,咱不演示)
使用spatial参数可以设置空间索引,空间索引只能创建在空间数据类型上,这样可以提高系统获取空间数据的效率,只有MYISAM引擎支持该索引,mysql默认引擎不支持
(上面是在创建数据表的时候创建索引,下面介绍一下在已存在的表上创建索引)
73:在已经创建好的数据表上面创建索引如下图所示

 (在已经创建好的数据表上面创建唯一索引如下图所示)
(在已经创建好的数据表上面创建唯一索引如下图所示)

(在已经创建好的数据表上面创建多列索引如下图所示)

74:使用ALTER TABLE来创建索引

(使用ALTER TABLE来创建唯一索引)

(使用ALTER TABLE来创建多列索引)

75:删除索引

76:视图的引入
1:视图是一种虚拟的表,是从数据库中一个或者多个表中导出来的表
2:数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中
3:使用视图查询数据时,数据库系统会从原来的表中取出对应的数据
77:视图的作用
1:使操作简便化
2:增加数据的安全性
3:提高表的逻辑独立性
78:创建视图
(然后使用创建的视图进行查询即可查询出数据表里面的内容)

(上面创建的视图然后进行查询好像意义不大,下面创建视图v2,然后对数据表里面的部分内容进行查询,增加安全性)

(然后使用创建的视图进行查询即可查询出数据表里面的内容)

(也可以利用视图修改名字,如下图)

(然后使用创建的视图进行查询即可查询出数据表里面的内容)

79:多表视图的创建

(然后使用创建的视图进行查询即可查询出数据表里面的内容)

80:查看视图的基本信息
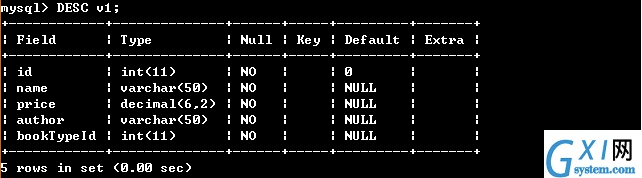
81:查看视图的基本信息,对比显示出视图是一个虚表


82:查看视图的详细信息

83:CREATE修改视图,如果视图不存在则创建,如果存在则修改

(然后使用修改后的视图进行查询即可查询出数据表里面的内容)

84:ALTER修改视图。

(然后使用修改后的视图进行查询即可查询出数据表里面的内容)

85:更新视图
更新视图是指通过视图来插入(INSERT),更新(UPDATE),删除(DELETE)表中的数据,因为视图是一个虚拟的表,其中没有数据。通过视图更新时,都是转换基本表更新。更新视图时,只能更新权限范围内的数据,超出了范围,就不能更新
插入(INSERT),


更新(UPDATE),


删除(DELETE)

86:删除视图
删除视图是指删除数据库中的已经存在的视图,删除视图时,只能删除视图的定义,不会删除数据;(视图是虚表)
87:触发器(TRIGGER)的引入
触发器是由事件来触发某个操作,这些事件包括INSERT语句,UPDATE语句,DELETE语句。当数据库系统执行这些事件时,就会激活触发器执行相应的操作
88:创建与使用触发器
创建只有一个执行语句的触发器
(过度变量new或者old,就是刚刚插入的那条数据,具体的一条数据。)

(然后执行插入语句,可以在图形化工具中快速看到插入数据后,另一个表发生了变化)

(创建多个执行语句的触发器)
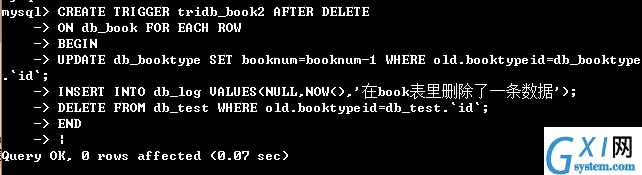
(然后执行删除语句,可以在图形化工具中快速看到插入数据后,另两个表发生了变化)

89:查看触发器
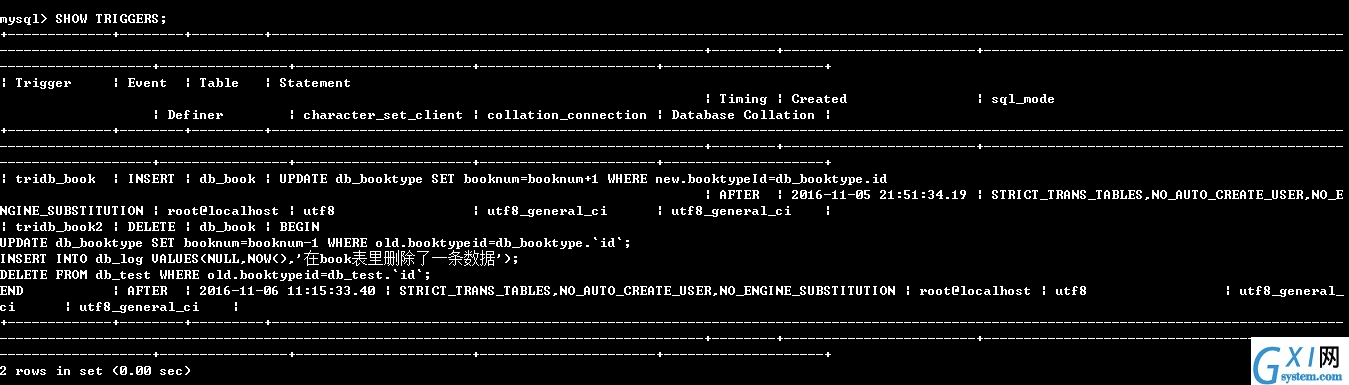
90:删除触发器




























