python爬虫需要安装什么
时间:2019-12-28 11:47
世界上80%的爬虫是基于Python开发的,学好爬虫技能,可为后续的大数据分析、挖掘、机器学习等提供重要的数据源。 python爬虫需要安装相关库: python爬虫涉及的库: 请求库,解析库,存储库,工具库 1. 请求库:urllib/re/requests (1) urllib/re是python默认自带的库,可以通过以下命令进行验证: 没有报错信息输出,说明环境正常 (2) requests安装 2.1 打开CMD,输入 2.2 等待安装后,验证 (3) selenium安装(驱动浏览器进行网站访问行为) 3.1 打开CMD,输入 3.2 安装chromedriver 网址:https://npm.taobao.org/ 把下载完成后的压缩包解压,把exe放到D:\Python3.6.0\Scripts\ 这个路径只要在PATH变量中就可以 3.3 等待安装完成后,验证 回车后弹出chrome浏览器界面 3.4 安装其他浏览器 无界面浏览器phantomjs 下载网址:http://phantomjs.org/ 下载完成后解压,把整个目录放到D:\Python3.6.0\Scripts\,把bin目录的路径添加到PATH变量 验证: 打开CMD 2. 解析库: 2.1 lxml (XPATH) 打开CMD 或者从https://pypi.python.org下载,例如,lxml-4.1.1-cp36-cp36m-win_amd64.whl (md5) ,先下载whl文件 2.2 beautifulsoup 打开CMD,需要先安装好lxml 验证 2.3 pyquery(类似jquery语法) 打开CMD 验证安装结果 3. 存储库 3.1 pymysql(操作MySQL,关系型数据库) 安装: 安装后测试: 3.2 pymongo(操作MongoDB,key-value) 安装 验证 3.3 redis(分布式爬虫,维护爬取队列) 安装: 验证: 4.工具库 4.1 flask(WEB库) 4.2 Django(分布式爬虫维护系统) 4.3 jupyter(运行在网页端的记事本,支持markdown,可以在网页上运行代码) 验证: 打开CMD 之后就可以在网页直接创建记事本,代码块和Markdown块,支持打印 【相关推荐】 1. python爬虫库以及相关利器 2. python爬虫入门教程 以上就是python爬虫需要安装什么的详细内容,更多请关注gxlsystem.com其它相关文章!
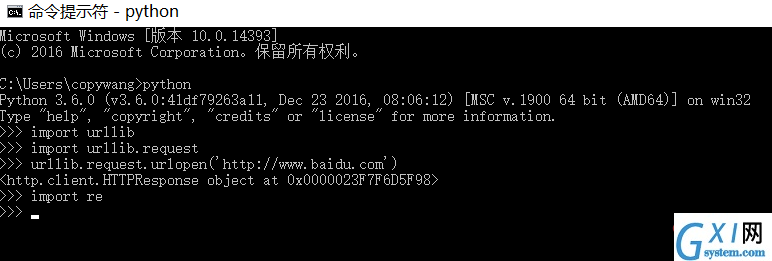
pip3 install requests

pip3 install selenium

phantomjs
console.log('phantomjs')
CTRL+C
python
from selenium import webdriver
driver = webdriver.PhantomJS()
dirver.get('http://www.baidu.com')
driver.page_sourcepip3 install lxml
pip3 install 文件名.whl
pip3 install beautifulsoup4
python
from bs4 import BeautifulSoup
soup = BeautifulSoup('<html></html>','lxml')pip3 install pyquery
python
from pyquery import PyQuery as pq
doc = pq('<html>hi</html>')
result = doc('html').text()
result
pip3 install pymysql
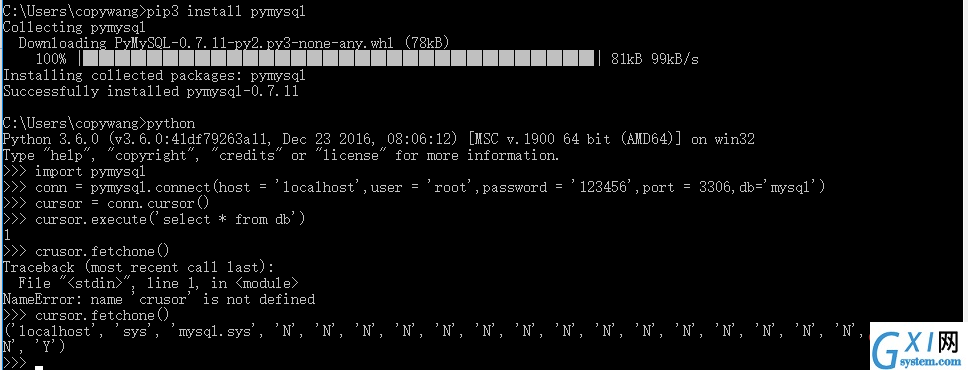
pip3 install pymongo
python
import pymongo
client = pymongo.MongoClient('localhost')
db = client['testdb']
db['table'].insert({'name':'bob'})
db['table'].find_one({'name':'bob'})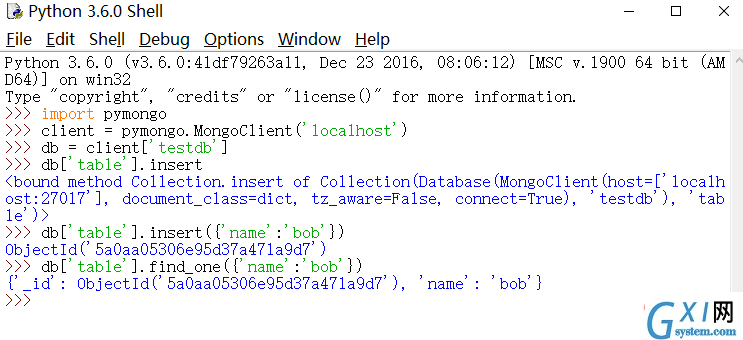
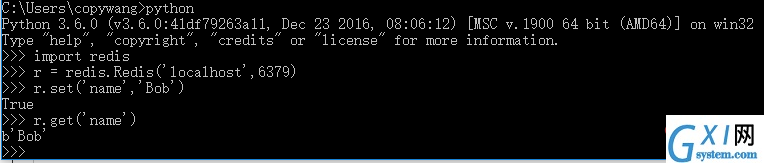
pip3 install redis
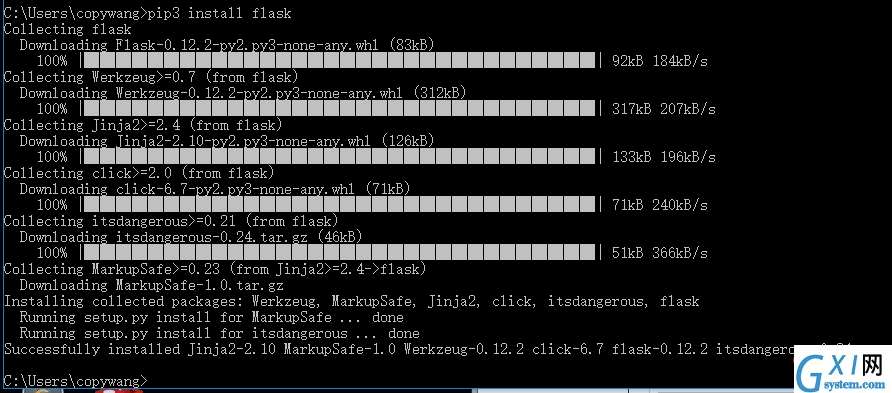
pip3 install flask
pip3 install django
pip3 install jupyter
jupyter notebook



























