怎么用两行Python代码实现pdf转word功能
时间:2023-04-28 18:32
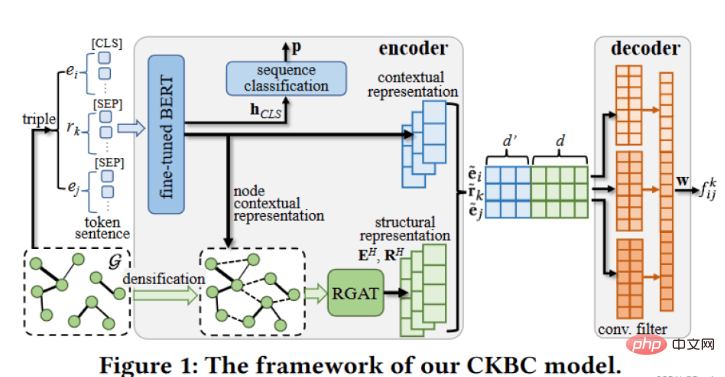
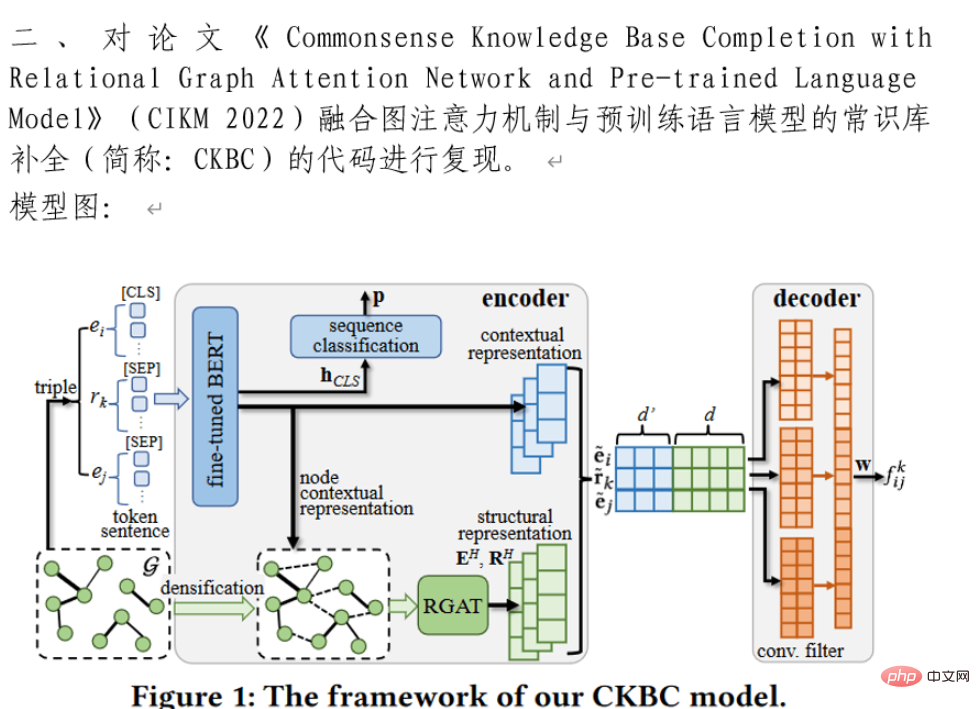
运行过程如下: [1/4] Opening document... 由上可见,效果还不错。 除了上文的办法,小编还为大家整理了更多Python实现的PDF转Word方法,需要的可以参考一下 方法一: 方法二: 加密过的PDF转word 以上就是怎么用两行Python代码实现pdf转word功能的详细内容,更多请关注Gxl网其它相关文章!一、安装依赖包
pip install --index https://pypi.mirrors.ustc.edu.cn/simple/ python-office
二、pdf转word
2.1 代码实现
import officeoffice.pdf.pdf2docx(file_path = 'test.pdf')
[INFO] [2/4] Analyzing document...
[WARNING] 'created' timestamp seems very low; regarding as unix timestamp
[WARNING] 'modified' timestamp seems very low; regarding as unix timestamp
[WARNING] 'created' timestamp seems very low; regarding as unix timestamp
[WARNING] 'modified' timestamp seems very low; regarding as unix timestamp
[INFO] [3/4] Parsing pages...
[INFO] (1/9) Page 1
[INFO] (2/9) Page 2
[INFO] (3/9) Page 3
[INFO] (4/9) Page 4
[INFO] (5/9) Page 5
[INFO] (6/9) Page 6
[INFO] (7/9) Page 7
[INFO] (8/9) Page 8
[INFO] (9/9) Page 9
[INFO] [4/4] Creating pages...
[INFO] (1/9) Page 1
[INFO] (2/9) Page 2
[INFO] (3/9) Page 3
[INFO] (4/9) Page 4
[INFO] (5/9) Page 5
[INFO] (6/9) Page 6
[INFO] (7/9) Page 7
[INFO] (8/9) Page 8
[INFO] (9/9) Page 9
[INFO] Terminated in 1.30s.
Process finished with exit code 02.2 pdf内容
2.3 转换后的word
补充
import osfrom configparser import ConfigParserfrom io import StringIOfrom io import openfrom concurrent.futures import ProcessPoolExecutorfrom pdfminer.pdfinterp import PDFResourceManagerfrom pdfminer.pdfinterp import process_pdffrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom docx import Documentdef read_from_pdf(file_path): with open(file_path, 'rb') as file: resource_manager = PDFResourceManager() return_str = StringIO() lap_params = LAParams() device = TextConverter( resource_manager, return_str, laparams=lap_params) process_pdf(resource_manager, device, file) device.close() content = return_str.getvalue() return_str.close() return contentdef save_text_to_word(content, file_path): doc = Document() for line in content.split('
'): paragraph = doc.add_paragraph() paragraph.add_run(remove_control_characters(line)) doc.save(file_path)def remove_control_characters(content): mpa = dict.fromkeys(range(32)) return content.translate(mpa)def pdf_to_word(pdf_file_path, word_file_path): content = read_from_pdf(pdf_file_path) save_text_to_word(content, word_file_path)def main(): config_parser = ConfigParser() config_parser.read('config.cfg') config = config_parser['default'] tasks = [] with ProcessPoolExecutor(max_workers=int(config['max_worker'])) as executor: for file in os.listdir(config['pdf_folder']): extension_name = os.path.splitext(file)[1] if extension_name != '.pdf': continue file_name = os.path.splitext(file)[0] pdf_file = config['pdf_folder'] + '/' + file word_file = config['word_folder'] + '/' + file_name + '.docx' print('正在处理: ', file) result = executor.submit(pdf_to_word, pdf_file, word_file) tasks.append(result) while True: exit_flag = True for task in tasks: if not task.done(): exit_flag = False if exit_flag: print('完成') exit(0)if __name__ == '__main__': main()#-*- coding: UTF-8 -*- #!/usr/bin/python#-*- coding: utf-8 -*-import sysimport importlibimportlib.reload(sys)from pdfminer.pdfparser import PDFParser,PDFDocumentfrom pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreterfrom pdfminer.converter import PDFPageAggregatorfrom pdfminer.layout import *from pdfminer.pdfinterp import PDFTextExtractionNotAllowedimport os#设置工作目录文件夹os.chdir(r'c:/users/dicey/desktop/codes/pdf-docx')#解析pdf文件函数def parse(pdf_path): fp = open('diya.pdf', 'rb') # 以二进制读模式打开 # 用文件对象来创建一个pdf文档分析器 parser = PDFParser(fp) # 创建一个PDF文档 doc = PDFDocument() # 连接分析器 与文档对象 parser.set_document(doc) doc.set_parser(parser) # 提供初始化密码 # 如果没有密码 就创建一个空的字符串 doc.initialize() # 检测文档是否提供txt转换,不提供就忽略 if not doc.is_extractable: raise PDFTextExtractionNotAllowed else: # 创建PDf 资源管理器 来管理共享资源 rsrcmgr = PDFResourceManager() # 创建一个PDF设备对象 laparams = LAParams() device = PDFPageAggregator(rsrcmgr, laparams=laparams) # 创建一个PDF解释器对象 interpreter = PDFPageInterpreter(rsrcmgr, device) # 用来计数页面,图片,曲线,figure,水平文本框等对象的数量 num_page, num_image, num_curve, num_figure, num_TextBoxHorizontal = 0, 0, 0, 0, 0 # 循环遍历列表,每次处理一个page的内容 for page in doc.get_pages(): # doc.get_pages() 获取page列表 num_page += 1 # 页面增一 interpreter.process_page(page) # 接受该页面的LTPage对象 layout = device.get_result() for x in layout: if isinstance(x,LTImage): # 图片对象 num_image += 1 if isinstance(x,LTCurve): # 曲线对象 num_curve += 1 if isinstance(x,LTFigure): # figure对象 num_figure += 1 if isinstance(x, LTTextBoxHorizontal): # 获取文本内容 num_TextBoxHorizontal += 1 # 水平文本框对象增一 # 保存文本内容 with open(r'test2.doc', 'a',encoding='utf-8') as f: #生成doc文件的文件名及路径 results = x.get_text() f.write(results) f.write('
') print('对象数量:
','页面数:%s
'%num_page,'图片数:%s
'%num_image,'曲线数:%s
'%num_curve,'水平文本框:%s
' %num_TextBoxHorizontal)if __name__ == '__main__': pdf_path = r'diya.pdf' #pdf文件路径及文件名 parse(pdf_path)
















热门排行
今日推荐






热门手游
-
商场购物模拟器官方版

版本:v1.0.9
大小:46.11MB
日期:2024-12-16
-
滚动方块大冒险免费版

版本:v1.0.5
大小:26.10MB
日期:2024-12-16
-
恋恋奇缘体验服版

版本:v1.0.0
大小:131.33MB
日期:2024-12-16
-
炉石传说官方正版

版本:v1.0
大小:100.52MB
日期:2024-12-16
-
人群大师免费版

版本:v2.15.0
大小:57.68MB
日期:2024-12-16
-
方鸡跳跑单机版

版本:v1
大小:63.49MB
日期:2024-12-16