如何用Python的Pandas库处理Excel数据?
时间:2023-05-09 00:18
原始内容如下: a)读取第n个Sheet(子表,在左下方可以查看或增删子表)的数据 可以注意到,原始表格左上角没有填入内容,读取的结果是“Unnamed: 0” ,这是由于read_excel函数会默认把表格的第一行为列索引名。另外,对于行索引名来说,默认从第二行开始编号(因为默认第一行是列索引名,所以默认第一行不是数据),如果不特意指定,则自动从0开始编号,如下。 b)列索引名还可以自定义,如下: c)也可以指定第n列为行索引名,如下: d)读取时跳过第n行的数据 1、直接加方括号索引 可以使用方括号加列名的方式 [col_name] 来提取某列的数据,然后再用方括号加索引数字 [index] 来索引这列的具体位置的值。这里索引名为name1的列,然后打印位于该列第1行(索引是1)位置的数据:4,如下: 2、iloc方法,按整数编号索引 使用 sheet.iloc[ ] 索引,方括号内为行列的整数位置编号(除去作为行索引的那一列和作为列索引的哪一行后,从 0 开始编号)。 b)sheet.iloc[0: 2] :提取前两行数据 c)sheet.iloc[0:2, 0:2] :通过分片的方式提取 前两行 的 前两列 数据 3、loc方法,按行列名称索引 使用 sheet.loc[ ] 索引,方括号内为行列的名称字符串。具体使用方式同 iloc ,只是把 iloc 的整数索引替换成了行列的名称索引。这种索引方式用起来更直观。 注意:iloc[1: 2] 是不包含2的,但是 loc['row1': 'row2'] 是包含 'row2' 的。 1、使用 numpy 库的 isnan() 或 pandas 库的 isnull() 方法判断是否等于 nan 。 2、使用 str() 转为字符串,判断是否等于 'nan' 。 下面的代码意会一下吧 sheet['name2'].replace(2, 100, inplace=True) :把 name2 列的元素 2 改为元素 100,原位操作。 sheet['name2'].replace(np.nan, 100, inplace=True) :把 name2 列的空元素(nan)改为元素 100,原位操作。 增加列,直接使用中括号 [ 要添加的名字 ] 添加。 sheet['name_add'] = [55, 66, 77] :添加名为 name_add 的列,值为[55, 66, 77] a)del(sheet['name3']) :使用 del 方法删除 b)sheet.drop('row1', axis=0) 使用 drop 方法删除 row1 行,删除列的话对应的 axis=1。 当 inplace 参数为 True 时,不会返回参数,直接在原数据上删除 当 inplace 参数为 False (默认)时不会修改原数据,而是返回修改后的数据 c)sheet.drop(labels=['name1', 'name2'], axis=1) 使用 label=[ ] 参数可以删除多行或多列 1、把 pandas 格式的数据另存为 .xlsx 文件 2、把改好的 excel 文件另存为 .xlsx 文件。 比如修改原表格中的 nan 为 100 后,保存文件: 打开 test2.xlsx 结果如下: 以上就是如何用Python的Pandas库处理Excel数据?的详细内容,更多请关注Gxl网其它相关文章!1、读取xlsx表格:pd.read_excel()
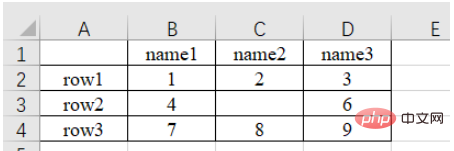
import pandas as pd# 每次都需要修改的路径path = "test.xlsx"# sheet_name默认为0,即读取第一个sheet的数据sheet = pd.read_excel(path, sheet_name=0)print(sheet)""" Unnamed: 0 name1 name2 name30 row1 1 2.0 31 row2 4 NaN 62 row3 7 8.0 9"""
sheet = pd.read_excel(path)# 查看列索引名,返回列表形式print(sheet.columns.values)# 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式print(sheet.index.values)"""['Unnamed: 0' 'name1' 'name2' 'name3'][0 1 2]"""
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4'])print(sheet)# 查看列索引名,返回列表形式print(sheet.columns.values)""" col1 col2 col3 col40 row1 1 2.0 31 row2 4 NaN 62 row3 7 8.0 9['col1' 'col2' 'col3' 'col4']"""
# 指定第一列为行索引sheet = pd.read_excel(path, index_col=0)print(sheet)""" name1 name2 name3row1 1 2.0 3row2 4 NaN 6row3 7 8.0 9"""
# 跳过第2行的数据(第一行索引为0)sheet = pd.read_excel(path, skiprows=[1])print(sheet)""" Unnamed: 0 name1 name2 name30 row2 4 NaN 61 row3 7 8.0 9"""
2、获取表格的数据大小:shape
path = "test.xlsx"# 指定第一列为行索引sheet = pd.read_excel(path, index_col=0)print(sheet)print('==========================')print('shape of sheet:', sheet.shape)""" name1 name2 name3row1 1 2.0 3row2 4 NaN 6row3 7 8.0 9==========================shape of sheet: (3, 3)"""3、索引数据的方法:[ ] / loc[] / iloc[]
sheet = pd.read_excel(path)# 读取列名为 name1 的列数据col = sheet['name1']print(col)# 打印该列第二个数据print(col[1]) # 4"""0 11 42 7Name: name1, dtype: int644"""
a)sheet.iloc[1, 2] :提取第2行第3列数据。第一个是行索引,第二个是列索引# 指定第一列数据为行索引sheet = pd.read_excel(path, index_col=0)# 读取第2行(row2)的第3列(6)数据# 第一个是行索引,第二个是列索引data = sheet.iloc[1, 2]print(data) # 6print('================================')# 通过分片的方式提取 前两行 数据data_slice = sheet.iloc[0:2]print(data_slice)print('================================')# 通过分片的方式提取 前两行 的 前两列 数据data_slice = sheet.iloc[0:2, 0:2]print(data_slice)"""6================================ name1 name2 name3row1 1 2.0 3row2 4 NaN 6================================ name1 name2row1 1 2.0row2 4 NaN"""# 指定第一列数据为行索引sheet = pd.read_excel(path, index_col=0)# 读取第2行(row2)的第3列(6)数据# 第一个是行索引,第二个是列索引data = sheet.loc['row2', 'name3']print(data) # 1print('================================')# 通过分片的方式提取 前两行 数据data_slice = sheet.loc['row1': 'row2']print(data_slice)print('================================')# 通过分片的方式提取 前两行 的 前两列 数据data_slice1 = sheet.loc['row1': 'row2', 'name1': 'name2']print(data_slice1)"""6================================ name1 name2 name3row1 1 2.0 3row2 4 NaN 6================================ name1 name2row1 1 2.0row2 4 NaN"""4、判断数据为空:np.isnan() / pd.isnull()
sheet = pd.read_excel(path)# 读取列名为 name1 的列数据col = sheet['name2'] print(np.isnan(col[1])) # Trueprint(pd.isnull(col[1])) # True"""TrueTrue"""
sheet = pd.read_excel(path)# 读取列名为 name1 的列数据col = sheet['name2']print(col)# 打印该列第二个数据if str(col[1]) == 'nan': print('col[1] is nan')"""0 2.01 NaN2 8.0Name: name2, dtype: float64col[1] is nan"""5、查找符合条件的数据
# 提取name1 == 1 的行mask = (sheet['name1'] == 1)x = sheet.loc[mask]print(x)""" name1 name2 name3row1 1 2.0 3"""
6、修改元素值:replace()
sheet['name2'].replace(2, 100, inplace=True)print(sheet)""" name1 name2 name3row1 1 100.0 3row2 4 NaN 6row3 7 8.0 9"""
import numpy as np sheet['name2'].replace(np.nan, 100, inplace=True)print(sheet)print(type(sheet.loc['row2', 'name2']))""" name1 name2 name3row1 1 2.0 3row2 4 100.0 6row3 7 8.0 9"""
7、增加数据:[ ]
path = "test.xlsx"# 指定第一列为行索引sheet = pd.read_excel(path, index_col=0)print(sheet)print('====================================')# 添加名为 name_add 的列,值为[55, 66, 77]sheet['name_add'] = [55, 66, 77]print(sheet)""" name1 name2 name3row1 1 2.0 3row2 4 NaN 6row3 7 8.0 9==================================== name1 name2 name3 name_addrow1 1 2.0 3 55row2 4 NaN 6 66row3 7 8.0 9 77"""8、删除数据:del() / drop()
sheet = pd.read_excel(path, index_col=0)# 使用 del 方法删除 'name3' 的列del(sheet['name3'])print(sheet)""" name1 name2row1 1 2.0row2 4 NaNrow3 7 8.0"""
sheet.drop('row1', axis=0, inplace=True)print(sheet)""" name1 name2 name3row2 4 NaN 6row3 7 8.0 9"""# 删除多列,默认 inplace 参数位 False,即会返回结果print(sheet.drop(labels=['name1', 'name2'], axis=1))""" name3row1 3row2 6row3 9"""
9、保存到excel文件:to_excel()
names = ['a', 'b', 'c']scores = [99, 100, 99]result_excel = pd.DataFrame()result_excel["姓名"] = namesresult_excel["评分"] = scores# 写入excelresult_excel.to_excel('test3.xlsx')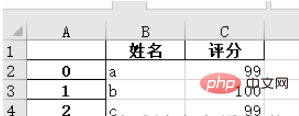
import numpy as np # 指定第一列为行索引sheet = pd.read_excel(path, index_col=0)sheet['name2'].replace(np.nan, 100, inplace=True)sheet.to_excel('test2.xlsx')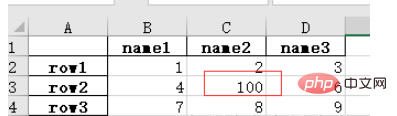
















热门排行
今日推荐






热门手游
-
商场购物模拟器官方版

版本:v1.0.9
大小:46.11MB
日期:2024-12-16
-
滚动方块大冒险免费版

版本:v1.0.5
大小:26.10MB
日期:2024-12-16
-
恋恋奇缘体验服版

版本:v1.0.0
大小:131.33MB
日期:2024-12-16
-
炉石传说官方正版

版本:v1.0
大小:100.52MB
日期:2024-12-16
-
人群大师免费版

版本:v2.15.0
大小:57.68MB
日期:2024-12-16
-
方鸡跳跑单机版

版本:v1
大小:63.49MB
日期:2024-12-16