怎么使用Python写一个简单的JSONParser
时间:2023-05-13 00:36
JSON 的词法分析,我主要是参考上面这个截图里面的方式,自己写了一个简单的示例。写得比较简单,应该说它只能支持 JSON 的一个简单子集。 这里 TOKEN 的种类,参考了 https://json.org,不过它的 JSON 的语法格式是带 whitespace 的,我不习惯处理这个,所以没有参考它的语法。经过词法分析之后,过滤掉了 空格、换行、制表符,我这里就是简单的丢弃不处理。 json_tokenizer.py 使用正则表达式来进行 JSON 的词法分析。 我这里把输入、输出数据全部放在文档里面了,下面我贴一下我输入数据和部分输出数据。 demo.json json_token.json 部分数据,数据我格式化了,所以比较长,这里只截取一部分。 json_parser.py 对上一步生成的 token 序列,进行 parser,生成 JSON 对应的 Dict 对象。parser 的实现参考了 antlr4 的 json 语法文件,它去掉了 whitespace,处理起来更简单一点。 输出结果: 以上就是怎么使用Python写一个简单的JSONParser的详细内容,更多请关注Gxl网其它相关文章!JSON Tokenizer
import jsonimport refrom typing import Dict, List, Union# TOKEN 的种类LEFT_BRACE = "LEFT_BRACE" # {RIGHT_BRACE = "RIGHT_BRACE" # }LEFT_BRACKET = "LEFT_BRACKET" # ]RIGHT_BRACKET = "RIGHT_BRACKET" # [COLON = "COLON" # :COMMA = "COMMA" # ,NUMBER = "NUMBER" # ".*?"STRING = "STRING" # [1-9]d*BOOL = "BOOL" # true/falseNULL = "NULL" # nullNEWLINE = "NEWLINE" #
SKIP = "SKIP" # ' ', ' 'MISMATCH = "MISMATCH" # mismatch# 处理 token 的正则token_specification = [ ('LEFT_BRACE', r'[{]'), ('RIGHT_BRACE', r'[}]'), ('LEFT_BRACKET', r'[[]'), ('RIGHT_BRACKET', r'[]]'), ('COLON', r'[:]'), ('COMMA', r'[,]'), ('NUMBER', r'-?[1-9]+[0-9]*'), ('STRING', r'".*?"'), ('BOOL', r'(true)|(false)'), ('NULL', r'null'), ('NEWLINE', r'
'), ('SKIP', r'[ ]'), ('MISMATCH', r'.')]tok_regex = '|'.join('(?P<%s>%s)' % pair for pair in token_specification)print("Debug: ", tok_regex)def process(kind: str, value: str) -> Dict[str, Union[str, bool, int, None]]: """ 处理输入的 kind 和 value,并生成 Dict 对象,简单表示 token 对象 """ if kind == STRING: # 去掉外层的双引号,暂时没有比较好的方式 return {"kind": kind, "value": value[1:-1]} if kind == NUMBER: return {"kind": kind, "value": int(value)} if kind == BOOL: if value == "true": return {"kind": kind, "value": True} else: return {"kind": kind, "value": False} if kind == NULL: return {"kind": kind, "value": None} return {"kind": kind, "value": value}def tokenizer(json_str: str) -> List[Dict[str, Union[str, bool, int, None]]]: """ tokenizer """ tokens = [] for m in re.finditer(tok_regex, json_str): # 获取 token 的类型 kind = m.lastgroup # 获取 token 的值 value = m.group() if kind == MISMATCH: raise Exception("json format is error") if kind == NEWLINE: continue if kind == SKIP: continue token = process(kind=kind, value=value) tokens.append(token) return tokensif __name__ == "__main__": json_doc = open("./demo.json", "r", encoding="utf-8").read() tokens = tokenizer(json_doc) if tokens: json.dump(tokens, open("./json_tokens.json", "w", encoding="utf-8"), ensure_ascii=False){ "name": "小黑子", "age": 3, "gender": false, "other_info": { "friends": [ "嘎子", "潘叔", "狗" ], "declaration": "练习时长两年半", "hobbies": [ "唱", "跳", "rap", "篮球????" ] }}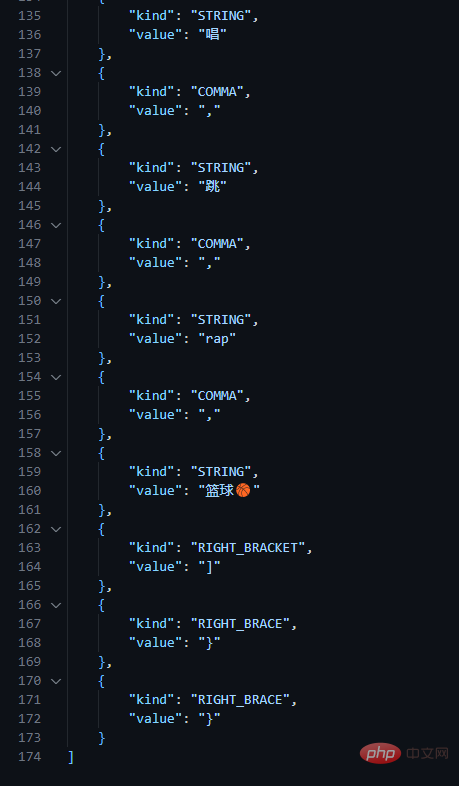
JSON Parser
import jsonfrom typing import Dict, Union# TOKEN 的种类LEFT_BRACE = "LEFT_BRACE" # {RIGHT_BRACE = "RIGHT_BRACE" # }LEFT_BRACKET = "LEFT_BRACKET" # ]RIGHT_BRACKET = "RIGHT_BRACKET" # [COLON = "COLON" # :COMMA = "COMMA" # ,NUMBER = "NUMBER" # ".*?"STRING = "STRING" # [1-9]d*BOOL = "BOOL" # true/falseNULL = "NULL" # nullclass Token(object): """为了简单,就不创建这个了"""class JSON_Parser(object): """ JSON_Parser the class aims parse input token sequence into a python object or array. """ def __init__(self, tokens) -> None: self.index = 0 self.tokens = tokens def get_token(self) -> Dict[str, Union[str, int, bool, None]]: """ get current's token """ if self.index < len(self.tokens): return self.tokens[self.index] else: raise Exception("index out of range.") def move_token(self) -> Dict[str, Union[str, int, bool, None]]: """ move to next token and return it """ if self.index + 1 < len(self.tokens): self.index = self.index + 1 return self.tokens[self.index] else: raise Exception("index out of range.") def parse(self): """ parse whole json """ token = self.get_token() if token.get("kind") == LEFT_BRACE: return self.parse_obj() elif token.get("kind") == LEFT_BRACKET: return self.parse_arr() else: raise Exception("error json, neither object or array.") def parse_obj(self): """ parse object """ obj = {} token = self.move_token() kind = token.get("kind") # '{' '}' if kind == RIGHT_BRACE: return obj # '{' pair (',' pair)* '}' name, val = self.parse_pair() obj[name] = val while self.index < len(self.tokens): token = self.move_token() kind = token.get("kind") if kind == COMMA: self.move_token() name, val = self.parse_pair() obj[name] = val elif kind == RIGHT_BRACE: return obj else: raise Exception("parse object encounter error") def parse_arr(self): """ parse array """ arr = [] token = self.move_token() kind = token.get("kind") # '[' ']' if kind == RIGHT_BRACE: return arr # '[' value (',' value)* ']' val = self.parse_value() arr.append(val) while self.index < len(self.tokens): token = self.move_token() kind = token.get("kind") if kind == COMMA: self.move_token() val = self.parse_value() arr.append(val) elif kind == RIGHT_BRACKET: return arr else: raise Exception("parse array encounter error") def parse_value(self): """ parse value """ token = self.get_token() kind = token.get("kind") if kind == LEFT_BRACE: return self.parse_obj() elif kind == LEFT_BRACKET: return self.parse_arr() elif kind == STRING or kind == NUMBER or kind == BOOL: return token.get("value") elif kind == NULL: return else: raise Exception("encounter unexcepted token") def parse_pair(self): """ parse pair """ token = self.get_token() kind = token.get("kind") name = token.get("value") # STRING ':' value if kind == STRING: token = self.move_token() kind = token.get("kind") if kind == COLON: token = self.move_token() return name, self.parse_value() raise Exception("parse pair encounter error")if __name__ == "__main__": # json token 文件路径 TOKEN_PATH = "./json_tokens.json" # 读取 token 序列 input_tokens = [token for token in json.load( open(TOKEN_PATH, "r", encoding="utf-8"))] if not input_tokens: raise Exception("input token sequence is empty") # 调试的时候,用来查表的,很方便定位到 index 走到哪一个 token 了 for i, tok in enumerate(input_tokens): print(f"debug {i:2d} --> {tok}") print("
===========================================
") parser = JSON_Parser(tokens=input_tokens) json_obj = parser.parse() # 再将 object 转成 json 并格式化后输出 print(json.dumps(json_obj, ensure_ascii=False, indent=4))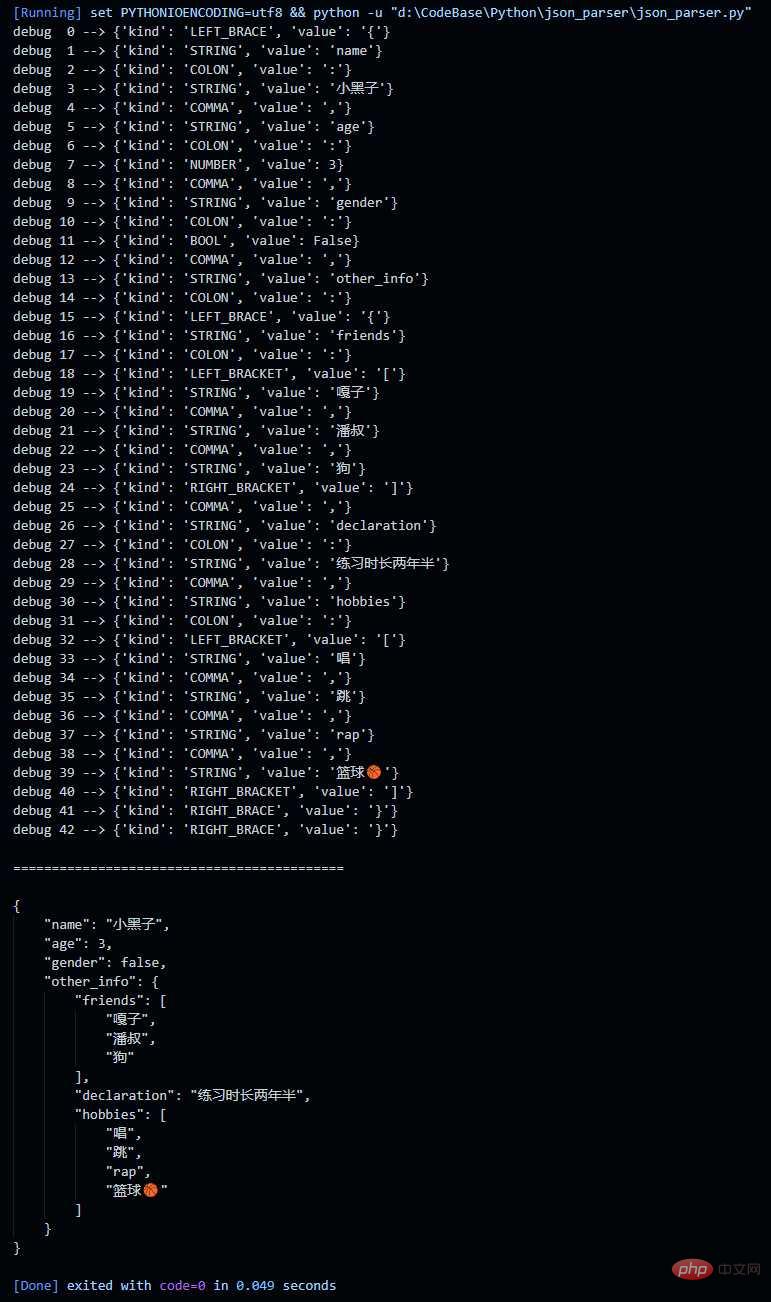
















热门排行
今日推荐






热门手游
-
商场购物模拟器官方版

版本:v1.0.9
大小:46.11MB
日期:2024-12-16
-
滚动方块大冒险免费版

版本:v1.0.5
大小:26.10MB
日期:2024-12-16
-
恋恋奇缘体验服版

版本:v1.0.0
大小:131.33MB
日期:2024-12-16
-
炉石传说官方正版

版本:v1.0
大小:100.52MB
日期:2024-12-16
-
人群大师免费版

版本:v2.15.0
大小:57.68MB
日期:2024-12-16
-
方鸡跳跑单机版

版本:v1
大小:63.49MB
日期:2024-12-16