Python中的数据清洗方法是什么
时间:2023-05-13 20:58
这里数据清洗需要用到的库是pandas库,下载方式还是在终端运行 : pip install pandas. 首先我们需要对数据进行读取 第3行是对数据进行读取,pandas库里面有读取函数调用即可,csv格式是读取写入速度最快的。 第4,5行是为了读取的实话显示全部的列,是因为很多列的话pycharm会把中间一些列隐藏掉,所以我们这为了他不隐藏就加这两行代码。 第6行是显示表头,我们可以看到有什么字段,列名 第7行是显示表的基本信息,每一列有多少数据,字段是什么类型的数据。非空的数据有多少,所以我们第一步就可以看得到基本那一列有空值了。 data.info()后我们可以看到大部分数据都有541909行,所以我们大致猜到是Description ,CustomerID 列漏结果了 第5行进行空值删除,这里先删除Description列的空值,inplace=True意思是对数据进行修改,如果没有inplace=True,则不对data进行修改,打印数据还是和之前一样,或者重新定义一个变量进行赋值。 由于这一列空值数据比较少,这一列数据对我们数据分析没有那么重要,所以我们选择删除这一整列。 我们这个表是对客户进行筛选的,所以以CustomerID为准,强制删除其他列 这里我们先对其他字段进行类型转换 类型转换 以上我们处理了空值,接下来我们处理异常值。 查看表的基本数据分布可以使用describe 可以看到数据Quantity 列中最小值为-80995.这列明显有异常值,所以需要对这一列进行异常值筛选。 只需要大于0的值。 打印一下就只有397924行了。 有5194行重复值,这里的重复值是完全重复的,所以是没用的数据我们可以进行删除。 删除后对原来的表进行保存,再去查看一下表的基本信息 现在还剩下392730条数据。数据到这一步就完成了数据清洗。 以上就是Python中的数据清洗方法是什么的详细内容,更多请关注Gxl网其它相关文章!import pandas as pd data = pd.read_csv(r'E:PYthon用户价值分析 RFM模型data.csv')pd.set_option('display.max_columns', 888) # 大于总列数pd.set_option('display.width', 1000)print(data.head())print(data.info())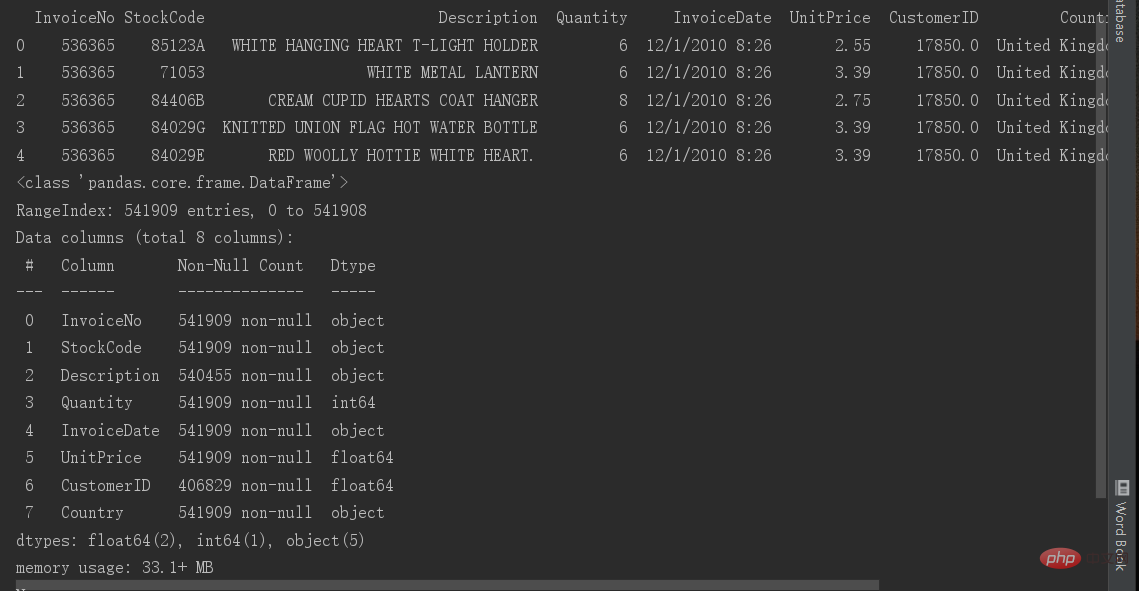
空值处理
# 空值处理print(data.isnull().sum()) # 空值中和,查看每一列的空值 # 空值删除data.drop(columns=['Description'], inplace=True)print(data.info())data.isnull()判断是否为空。data.isnumll().sum()计算空值数量。
# CustomerID有空值# 删除所有列的空值data.dropna(inplace=True)# print(data.info())print(data.isnull().sum()) # 由于CustomerID为必须字段,所以强制删除其他列,以CustomerID为准
# 转换为日期类型data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate']) # CustomerID 转换为整型data['CustomerID'] = data['CustomerID'].astype('int')print(data.info())异常值处理
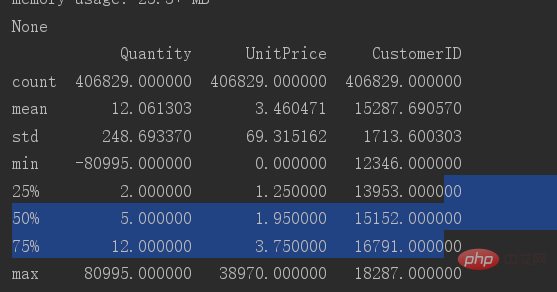
print(data.describe())
data = data[data['Quantity'] > 0]print(data)
重复值处理
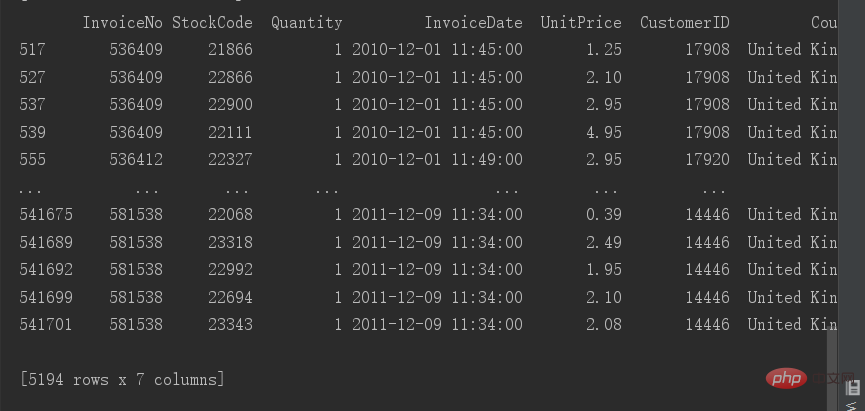
# 查看重复值print(data[data.duplicated()])
删除重复值
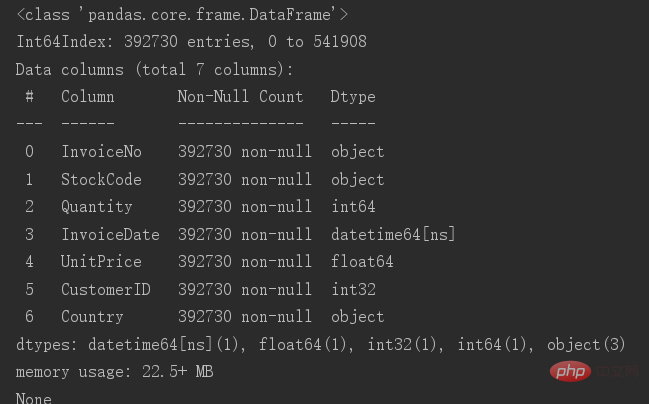
# 删除重复值data.drop_duplicates(inplace=True) print(data.info())
















热门排行
今日推荐






热门手游
-
商场购物模拟器官方版

版本:v1.0.9
大小:46.11MB
日期:2024-12-16
-
滚动方块大冒险免费版

版本:v1.0.5
大小:26.10MB
日期:2024-12-16
-
恋恋奇缘体验服版

版本:v1.0.0
大小:131.33MB
日期:2024-12-16
-
炉石传说官方正版

版本:v1.0
大小:100.52MB
日期:2024-12-16
-
人群大师免费版

版本:v2.15.0
大小:57.68MB
日期:2024-12-16
-
方鸡跳跑单机版

版本:v1
大小:63.49MB
日期:2024-12-16