Linux正则表达式grep与egrep
时间:2022-04-03 11:22
Linux正则表达式grep与egrep
正则表达式:它是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索或替换那些符合某个模式的文本内容。
其实正则表达式,只是一种思想,一种表示方法。只要我们使用的工具支持表示这种思想那么这个工具就可以处理正则表达式的字符串。常用的工具有grep, sed, awk,这三个都是针对文本的行才操作的。
grep 过滤器
语法: grep [-cinvABC] ‘word‘ filename
-n 显示行号
-c count统计符合要求的行数
-v 取反,不包含所选字符的
-i 不区分大小写
-r 会把目录下面所有的文件遍历 例如: grep -r ‘root‘ ./
-A 后面跟数字,A2表示打印符合要求的行及下面二行
-B 后面跟数字,B2表示打印符合要求的行及上面二行
-C 后面跟数字,C2表示打印符合要求的行及上下各二行
^ 行首,开头
$ 行尾,结尾
空行用 ^$ 表示
可以做一个别名alias grep="grep --color" 写入到.bashrc里面;以后输入grep命令时查找的关键字符会颜色显示,方便区分。
过滤带有某个关键词的行并输出行号,颜色显示关键词
[root@localhost ~]# grep -n --color ‘root‘ passwd
1:root:x:0:0:root:/root:/bin/bash
11:operator:x:11:0:operator:/root:/sbin/nologin
[root@localhost ~]# grep -o --color ‘root‘ passwd | wc -l
4
加-o 统计包含关键词的个数;
过滤不带有某个关键词的行,并输出行号;
[root@ linuxidc.com ~]# grep -nv ‘nologin‘ /etc/passwd
1:root:x:0:0:root:/root:/bin/bash
6:sync:x:5:0:sync:/sbin:/bin/sync
7:shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8:halt:x:7:0:halt:/sbin:/sbin/halt
20:user1:x:600:501::/home/user1:/bin/bash
23:mysql:x:27:27:MySQL Server:/var/lib/mysql:/bin/bash
过滤以nologin结尾的,系统禁止登陆的所有用户;
[root@localhost ~]# grep ‘nologin$‘ /etc/passwd
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
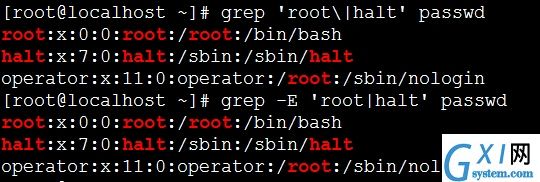
示例,打印关键字halt所在行的A2 B2 C2
[root@ linuxidc.com ~]# grep -A2 ‘halt‘ passwd
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
[root@ linuxidc.com ~]# grep -B2 ‘halt‘ passwd
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
[root@ linuxidc.com ~]# grep -C2 ‘halt‘ passwd
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
把所有以#号开头的行去除
[root@ linuxidc.com ~]# grep -v ‘^#‘ /etc/inittab
id:3:initdefault:
去除所有空行和以#号开头的行
[root@ linuxidc.com ~]# grep -v ‘^#‘ /etc/crontab |grep -v ‘^$‘
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
示例说明,打印数字或字母开头,及不是字母和数字开头的;
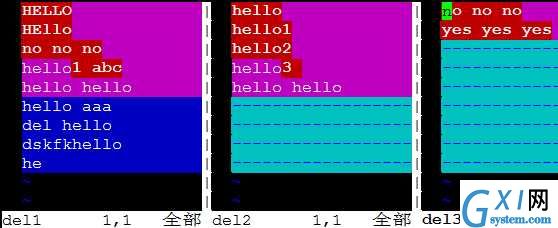
[root@ linuxidc.com tmp]# cat test.txt
helloworld
abc
abc11111
#differt
12345
67899
123def
[0-9]代表任意一个数字,整个命令意思筛选出包含任意一个数字的行;
[root@ linuxidc.com tmp]# grep ‘[0-9]‘ test.txt
abc11111
12345
67899
123def
[^0-9]代表除0-9之外的任意一个字符,整个命令的意思是筛选出不包含数字的行;
[root@ linuxidc.com tmp]# grep ‘[^0-9]‘ test.txt
helloworld
abc
abc11111
#differt
123def
^[^0-9]代表不是数字开头的;
[root@ linuxidc.com tmp]# grep ‘^[^0-9]‘ test.txt
helloworld
abc
abc11111
#differt
[a-z]代表任意一个英文字母;
[root@ linuxidc.com tmp]# grep ‘[a-z]‘ test.txt
helloworld
abc
abc11111
#differt
123def
[^a-z]代表除英文字母以外的;
[root@ linuxidc.com tmp]# grep ‘[^a-z]‘ test.txt
abc11111
#differt
12345
67899
123def
^[^a-z]代表不是英文字母开头的文本;
[root@ linuxidc.com tmp]# grep ‘^[^a-z]‘ test.txt
#differt
12345
67899
123def
[ ] 如果是数字的话就用[0-9]这样的形式,当然有时候也可以用这样的形式[15]即只含有1或者5,注意,它不会认为是15。如果要过滤出数字以及大小写 字母则要这样写[0-9a-zA-Z]。另外[ ]还有一种形式,就是[^字符] 表示除[ ]内的字符之外的字符。
过滤任意一个字符与重复字符
[root@ linuxidc.com ~]# grep ‘h..t‘ /etc/passwd
halt:x:7:0:halt:/sbin:/sbin/halt
‘.‘点表示任意的一个字符,上面例子为把符合h与t之间有2个任意字符的行过滤出来。
‘*‘代表零个或多个任意的字符
‘ooo*‘代表oo,ooo,oooo 或者更多的o
[root@ linuxidc.com ~]# grep ‘ooo*‘ /etc/passwd
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
‘.*‘表示零个或多个任意字符,等于所有的,空行也包含在内。
[root@ linuxidc.com ~]# grep ‘.*‘ /etc/passwd |wc -l
24
[root@ linuxidc.com ~]# wc -l /etc/passwd
24 /etc/passwd
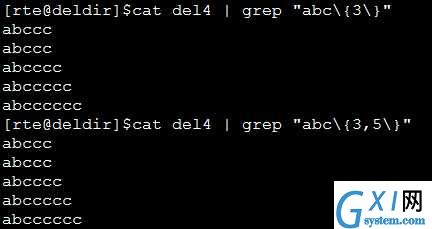
指定要过滤字符出现的次数
{ }内部为数字,表示前面字符要重复的次数。表示两个O即包含OO的行。{ }左右都需要加脱意字符\
grep -E 代表增强版的grep即egrep,使用egrep不需要脱意;
123456789 [root@ linuxidc.com ~]# grep ‘o\{2\}‘ /etc/passwd
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
[root@localhost ~]# grep -E ‘o{2}‘ passwd
[root@localhost ~]# egrep ‘o{2}‘ passwd
[root@ linuxidc.com ~]# cat test.txt
root:hot
abcde
spoool
spool
spol
spl
示例,过滤字母o出现1到3次的行
[root@ linuxidc.com ~]# grep ‘o\{1,3\}‘ test.txt
root:hot
spoool
spool
spol
{ } 还可以表示一个范围,格式为{n1,n2} n1<n2 表示重复n1到n2次前面的字符,n2还可以为空,则表示大于等于n1次。
egrep为grep的扩展版本,我们可以用egrep完成grep不能完成的工作,当然了grep能完成的egrep完全可以完成。
grep -E = egrep
1、筛选一个或一个以上前面的字符 字符后面使用+
[root@ linuxidc.com ~]# cat test.txt
rot:x:0:0:rot:/rot:/bin/bash
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
rooooot:x:0:0/roooooot:/bin/bash
11111111111111111111111111111111
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
[root@ linuxidc.com ~]# egrep ‘o+‘ test.txt
rot:x:0:0:rot:/rot:/bin/bash
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
rooooot:x:0:0/roooooot:/bin/bash
[root@ linuxidc.com ~]# egrep ‘oo+‘ test.txt
root:x:0:0:root:/root:/bin/bash
rooooot:x:0:0/roooooot:/bin/bash
[root@ linuxidc.com ~]# egrep ‘ooo+‘ test.txt
rooooot:x:0:0/roooooot:/bin/bash
2、筛选零个或一个前面的字符 字符后面使用?
[root@ linuxidc.com ~]# egrep ‘o?‘ test.txt
rot:x:0:0:rot:/rot:/bin/bash
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
rooooot:x:0:0/roooooot:/bin/bash
11111111111111111111111111111111
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
[root@ linuxidc.com ~]# egrep ‘oo?‘ test.txt
rot:x:0:0:rot:/rot:/bin/bash
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
rooooot:x:0:0/roooooot:/bin/bash
[root@ linuxidc.com ~]# egrep ‘ooo?‘ test.txt
root:x:0:0:root:/root:/bin/bash
rooooot:x:0:0/roooooot:/bin/bash
[root@ linuxidc.com ~]# egrep ‘oooo?‘ test.txt
rooooot:x:0:0/roooooot:/bin/bash
3、筛选字符串1或字符串2 包含里面任意一个字符串的打印出来
[root@ linuxidc.com ~]# egrep ‘aaa|111|ooo‘ test.txt
rooooot:x:0:0/roooooot:/bin/bash
11111111111111111111111111111111
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
4、egrep中()的应用
[root@ linuxidc.com ~]# egrep ‘r(oo)|(mo)n‘ test.txt
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
rooooot:x:0:0/roooooot:/bin/bash
用( )表示一个整体,例如(oo)+ 表示1个‘oo‘或者多个‘oo‘
[root@ linuxidc.com ~]# egrep ‘(oo)+‘ test.txt
root:x:0:0:root:/root:/bin/bash
rooooot:x:0:0/roooooot:/bin/bash
5、egrep中[ ]的应用
方括号内的字符为其中的一个;[^o]为除了字母o之外的;
示例:r开头t结尾的;;
[root@localhost ~]# egrep ‘r[o]t‘ test.txt
rot:x:0:0:rot:/rot:/bin/bash
r开头后面有o的
[root@localhost ~]# egrep ‘r[o]‘ test.txt
rot:x:0:0:rot:/rot:/bin/bash
root:x:0:0:root:/root:/bin/bash
rooooot:x:0:0/roooooot:/bin/bash
r开头后面不是o的;
[root@localhost ~]# egrep ‘r[^o]‘ test.txt
rrt
rtx
t为结尾的前面字符不是o的;
[root@localhost ~]# egrep ‘[^o]t‘ test.txt
rrt
rtx
. * + ? 符号的总结
. 表示任意一个字符(包括特殊字符 空格 # $ ?)
* 表示零个或多个*前面的字符
.* 表示任意个任意字符(包含空行)
+ 表示1个或多个+前面的字符
? 表示0个或1个?前面的字符
其中,+ ? grep不支持,egrep才支持。
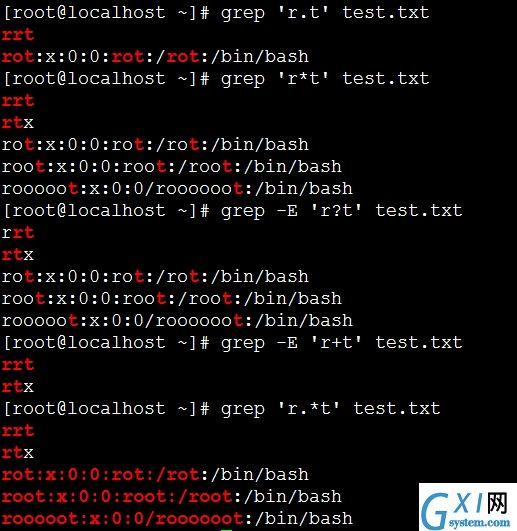
"ro.*t" 表示以ro开头一直到t结尾的
[root@localhost ~]# grep ‘ro.*t‘ test.txt
rot:x:0:0:rot:/rot:/bin/bash
root:x:0:0:root:/root:/bin/bash
rooooot:x:0:0/roooooot:/bin/bash
图片显示的更详细,方便大家理解。
grep如果需要筛选字符串 | 管道需要加脱意\才可以使用;
grep使用简明及正则表达式
Linux下Shell编程——grep命令的基本运用
grep 命令详解及相关事例
Linux基础命令之grep详解
设置grep高亮显示匹配项
Linux grep命令学习与总结
要用好grep这个工具,其实就是要写好正则表达式,所以这里不对grep的所有功能进行实例讲解,只列几个例子,讲解一个正则表达式的写法。 $ ls -l | grep ‘^d‘ $ grep ‘test‘ d* $ grep ‘test‘ aa bb cc $ grep ‘[a-z]\{5,\}‘ aa $grep ‘t[a|e]st’ filename 显示包含test或tast的所有行。 $grep ‘\.$‘ filename 显示以.为结尾的所有行。 1.1 基本用法 如: sed ‘s/day/night/‘ <old >new s " 替换 " 命令 sed -i ‘s/anonymous=YES/anonymous=NO/‘ /etc/vsftpd/vsftpd.conf 1.2 用 & 表示匹配的字符串 有时可能会想在匹配到的字符串周围或附近加上一些字符 . 该例子在找到的 abc 前后加上括号 . 下面是更复杂的例子 : sed 默认只替换搜索字符串的第一次出现 , 利用 /g 可以替换搜索字符串所有 $ sed‘s/test/mytest/g‘ example-----在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。 $ sed‘s/^192.168.0.1/&localhost/‘ example-----&符号表示替换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。 $ sed‘s#10#100#g‘ example-----不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。 如果需要对同一文件或行作多次修改,可以使用 "-e" 选项 取得eth0网卡IP地址: 2.删除行:d命令 从某文件中删除包含 "how" 的所有行 将/etc/passwd的内容显示并找印行号,同时将2~5删除 附:nl命令在系统中用来计算文件中行号。nl 可以将输出的文件内容自动的加上行号 如果只要删除第2行,可以使用nl /etc/passwd | sed ‘2d‘ 来达成,至于若是要删除第 3 到最后一行,则是nl /etc/passwd | sed ‘3,$d‘的啦。 3.增加行:a命令(在指定的行后新增)或i命令(在指定的行前新增) a的后面可以接字符串,而这些字符串会在新的一行出现 在/etc/passwd的第二行后增加“XXXXX”字样的新行 在/etc/passwd的第二行前增加“XXXXX”字样的新行 如果要同时新增多行,则每行之间要用反斜杠\来进行新行的添加 sed -i ‘/\[global\]/a test‘ /etc/samba/smb.conf sed -i ‘57a test‘ /etc/samba/smb.conf 4、取代行:c命令 c的后面可以接字符串,这些字符串可以取代n1,n2之间的行 5、打印:p命令 sed ‘/north/p‘ datafile 默认输出所有行,找到north的行重复打印 sed –n ‘/north/p‘ datafile 禁止默认输出,只打印找到north的行 nl /etc/passwd | sed -n ‘5,7p‘ 仅列出/etc/passwd文件中的第5~7行内容 注:sed 的-i选项可以直接修改文件中的内容 在一个awk脚本中可能有许多语句。 模式部分决定动作语句何时触发及触发事件。处理即对数据进行的操作。如果省略模式部分,动作将时刻保持执行状态。即省略时不对输入记录进行匹配比较就执行相应的actions。 模式可以是任何条件语句或正则表达式等。awk_pattern可以是以下几种类型: 1) 正则表达式用作awk_pattern: /regexp/ 例如:awk ‘/ ^[a-z]/‘ input_file 2) 布尔表达式用作awk_pattern,表达式成立时,触发相应的actions执行。 ① 表达式中可以使用变量(如字段变量$1,$2等)和/regexp/ ② 布尔表达式中的操作符: 关系操作符: < > <= >= == != ③ &&(与)和 ||(或) 可以连接两个/regexp/或者布尔表达式,构成混合表达式。!(非) 可以用于布尔表达式或者/regexp/之前。 例如: awk ‘($1 < 10 ) && ($2> 10) {print "ok"}‘ input_file 模式包括两个特殊字段 BEGIN和END。使用BEGIN语句设置计数和打印头。BEGIN语句使用在任何文本浏览动作之前,之后文本浏览动作依据输入文本开始执行。END语句用来在awk完成文本浏览动作后打印输出文本总数和结尾状态标志。 实际动作在大括号{ }内指明。动作大多数用来打印,但是还有些更长的代码诸如i f和循环语句及循环退出结构。如果不指明采取动作,awk将打印出所有浏览出来的记录。 awk执行时,其浏览域标记为$1,$2...$n。这种方法称为域标识。使用这些域标识将更容易对域进行进一步处理。 使用$1 , $3表示参照第1和第3域,注意这里用逗号做域分隔。如果希望打印一个有5个域 的记录的所有域,不必指明$1 ,$2 , $3 , $4 , $5,可使用$0,意即所有域。 为打印一个域或所有域,使用print命令。这是一个awk动作 awk的运行过程: ① 如果BEGIN区块存在,awk执行它指定的actions。 ② awk从输入文件中读取一行,称为一条输入记录。(如果输入文件省略,将从标准输入读取) ③ awk将读入的记录分割成字段,将第1个字段放入变量$1中,第2个字段放入$2,以此类推。$0表示整条记录。 ④ 把当前输入记录依次与每一个awk_cmd中awk_pattern比较,看是否匹配,如果相匹配,就执行对应的actions。如果不匹配,就跳过对应的actions,直到比较完所有的awk_cmd。 ⑤ 当一条输入记录比较了所有的awk_cmd后,awk读取输入的下一行,继续重复步骤③和④,这个过程一直持续,直到awk读取到文件尾。 ⑥ 当awk读完所有的输入行后,如果存在END,就执行相应的actions。 入门实例: 例1:显示/etc/passwd文件中的用户名和登录shell 如果只是显示/etc/passwd的账户和账户对应的shell,而账户与shell之间以tab键分割 如果只是显示/etc/passwd文件中的用户名和登录shell, 而账户与shell之间以逗号分割 注:awk的总是输出到标准输出,如果想让awk输出到文件,可以使用重定向。 例2:显示/etc/passwd文件中的UID大于500的所有用户的用户名和登录shell 例3:如果只是显示/etc/passwd文件中的UID大于500的用户名和登录shell,而账户与shell之间以逗号分割,而且在所有行添加列名name,shell,在最后一行添加"blue,/bin/nosh"。 注: 1.awk 后面接两个单引号并加上大括号 {} 来设定想要对数据进行的处理动作 2.awk工作流程是这样的:先执行BEGING,然后读取文件,读入有\n换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域,$1表示第一个域,$n表示第n个域,随后开始执行模式所对应的动作。接着开始读入第二条记录······直到所有的记录都读完,最后执行END操作。 思考题:如何打印所有记录(以/etc/passwd中的内容为例) 例4:搜索/etc/passwd有root关键字的所有行 这种是pattern(模式)的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。 搜索支持正则表达式,例如找root开头的: 搜索/etc/passwd有root关键字的所有行,并显示对应的shell 这里指定了action是{print $7} grep用法详解:grep与正则表达式 首先要记住的是: 正则表达式与通配符不一样,它们表示的含义并不相同! ◎grep -- print lines matching a pattern (将符合样式的该行列出)
◎语法: grep [options]
PATTERN [FILE...]
grep用以在file内文中比对相对应的部分,或是当没有指定档案时,
由标准输入中去比对。在预设的情况下,grep会将符合样式的那一行列出。 此外,还有两个程式是grep的变化型,egrep及fgrep。
其中egrep就等同於grep -E
,fgrep等同於grep -F
。 ◎参数 1. -A NUM,--after-context=NUM
除了列出符合行之外,并且列出後NUM行。
ex: $ grep -A 1 panda file
(从file中搜寻有panda样式的行,并显示该行的後1行)
2. -a或--text
grep原本是搜寻文字档,若拿二进位的档案作为搜寻的目标,
则会显示如下的讯息: Binary file 二进位档名 matches
然後结束。
若加上-a参数则可将二进位档案视为文字档案搜寻,
相当於--binary-files=text这个参数。
ex: (从二进位档案mv中去搜寻panda样式)
(错误!!!)
$ grep panda mv
Binary file mv matches
(这表示此档案有match之处,详见--binary-files=TYPE )
$
(正确!!!)
$ grep -a panda mv
3. -B NUM,--before-context=NUM
与 -A NUM 相对,但这此参数是显示除符合行之外
并显示在它之前的NUM行。
ex: (从file中搜寻有panda样式的行,并显示该行的前1行)
$ grep -B 1 panda file
4. -C [NUM], -NUM, --context[=NUM]
列出符合行之外并列出上下各NUM行,预设值是2。
ex: (列出file中除包含panda样式的行外并列出其上下2行)
(若要改变预设值,直接改变NUM即可)
$ grep -C[NUM] panda file
5. -b, --byte-offset
列出样式之前的内文总共有多少byte ..
ex: $ grep -b panda file
显示结果类似於:
0:panda
66:pandahuang
123:panda03
6. --binary-files=TYPE
此参数TYPE预设为binary(二进位),若以普通方式搜寻,只有2种结果:
1.若有符合的地方:显示Binary file
二进位档名 matches 2.若没有符合的地方:什麽都没有显示。
若TYPE为without-match,遇到此参数, grep会认为此二进位档案没有包含任何搜寻样式,与-I
参数相同。
若TPYE为text, grep会将此二进位档视为text档案,与-a
参数相同。 Warning: --binary-files=text
若输出为终端机,可能会产生一些不必要的输出。
7. -c, --count
不显示符合样式行,只显示符合的总行数。 若再加上-v,--invert-match,参数显示不符合的总行数。 8. -d ACTION, --directories=ACTION
若输入的档案是一个资料夹,使用ACTION去处理这个资料夹。 预设ACTION是read(读取),也就是说此资料夹会被视为一般的档案; 若ACTION是skip(略过),资料夹会被grep略过: 若ACTION是recurse(递),grep会去读取资料夹下所有的档案, 此相当於-r
参数。 9. -E, --extended-regexp
采用规则表示式去解释样式。 10. -e PATTERN, --regexp=PATTERN
把样式做为一个partern,通常用在避免partern用-开始。
11. -f FILE, --file=FILE
事先将要搜寻的样式写入到一个档案,一行一个样式。 然後采用档案搜寻。 空的档案表示没有要搜寻的样式,因此也就不会有任何符合。 ex: (newfile为搜寻样式档)
$grep -f newfile file
12. -G, --basic-regexp
将样式视为基本的规则表示式解释。(此为预设)
13. -H, --with-filename
在每个符合样式行前加上符合的档案名称,若有路径会显示路径。 ex: (在file与testfile中搜寻panda样式)
$grep -H panda file ./testfile
file:panda
./testfile:panda
$
14. -h, --no-filename
与-H参数相类似,但在输出时不显示路径。 15. --help
产生简短的help讯息。 16. -I grep会强制认为此二进位档案没有包含任何搜寻样式,
与--binary-files=without-match参数相同。
ex: $ grep -I panda mv
17. -i, --ignore-case
忽略大小写,包含要搜寻的样式及被搜寻的档案。
ex: $ grep -i panda mv
18. -L, --files-without-match
不显示平常一般的输出结果,反而显示出没有符合的档案名称。 19. -l, --files-with-matches
不显示平常一般的输出结果,只显示符合的档案名称。 20. --mmap
如果可能,使用mmap系统呼叫去读取输入,而不是预设的read系统呼叫。
在某些状况,--mmap 能产生较好的效能。然而,--mmap
如果运作中档案缩短,或I/O 错误发生时,
可能造成未定义的行为(包含core dump),。
21. -n, --line-number
在显示行前,标上行号。
ex: $ grep -n panda file
显示结果相似於下:
行号:符合行的内容 22. -q, --quiet, --silent
不显示任何的一般输出。请参阅-s或--no-messages
23. -r, --recursive
递地,读取每个资料夹下的所有档案,此相当於 -d recsuse
参数。 24. -s, --no-messages
不显示关於不存在或无法读取的错误讯息。 小:
不像GNU grep,传统的grep不符合POSIX.2协定, 因为缺乏-q参数,且他的-s
参数表现像GNU grep的 -q
参数。 Shell Script倾向将传统的grep移植,避开-q及-s参数, 且将输出限制到/dev/null。 POSIX: 定义UNIX及UNIX-like系统需要提供的功能。
25. -V, --version
显示出grep的版本号到标准错误。 当您在回报有关grep的bugs时,grep版本号是必须要包含在内的。 26. -v, --invert-match
显示除搜寻样式行之外的全部。
27. -w, --word-regexp
将搜寻样式视为一个字去搜寻,完全符合该"字"的行才会被列出。 28. -x, --line-regexp
grep参数 1.
-c 显示匹配的行数(就是显示有多少行匹配了); 2.
-n 显示匹配内容所在文档的行号; 3.
-i 匹配时忽略大小写; 4.
-s 错误信息不输出; 5.
-v 输出不匹配内容; 6.
-x 输出完全匹配内容; 7.
\ 忽略表达式中字符原有含义; 8.
^ 匹配表达式的开始行; 9.
$ 匹配表达式的结束行; 10.
\< 从匹配表达式的行开始; 11.
\> 到匹配表达式的行结束; 12.
[ ] 单个字符(如[A]
即A符合要求); 13.
[ - ] 范围;如[A-Z]即A,B,C一直到Z都符合要求; 14.
. 所有的单个字符;
15.
* 所有字符,长度可以为0; [精华] Grep
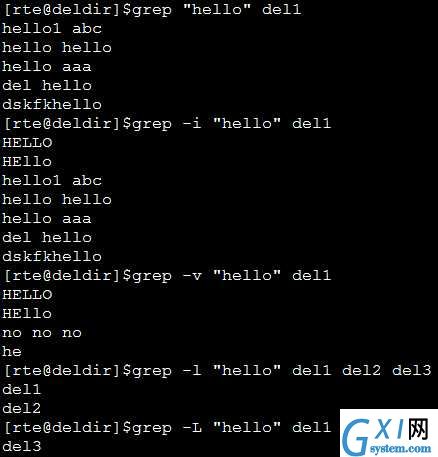
用法 何为转义:将特殊符号当普通符号来处理 笔记: 1.^在[]内外的含义 2.何时需要转义 3.*在bash中和正则表达式中本身的区别 4.-acinv 正则表达式是一种符号表示法,用于识别文本模式。Linux处理正则表达式的主要程序是grep。grep搜索与正则表达式匹配的行,并将结果输送至标准输出。 1. grep匹配模式 grep按下述方式接受选项和参数(其中,regex表示正则表达式) 其中options主要为下表: 举例说明 假设有三个文件del1、del2、del3三个文件的内容如下 例子 2. 特殊字符 3. 范围 注意:{}在郑则表达式中需要转移,而{}()不需要。 注意理解{}范围的例子: 4. 标准字符类 例子 可视化正则表达式 工具: 最近一直在研究shell脚本这块,刚好闲下来整了下自己手头上比较好的资料中的一些范例,以下是我整理的鸟哥私房菜里面正则表达式里面比较基础的一些语法详解,适合新手查阅。 首先先复制一段范例:
通过管道过滤ls-l输出的内容,只显示以d开头的行。
显示所有以d开头的文件中包含test的行。
显示在aa,bb,cc文件中匹配test的行。
显示所有包含每个字符串至少有5个连续小写字符的字符串的行。
该例子将文件 old 中的每一行第一次出现的 day 替换成 night, 将结果输出到文件 new
/../../ 分割符 (Delimiter)
day 搜索字符串
night 替换字符串
其实 , 分割符 "/" 可以用别的符号代替 , 比如 ",","|" 等 .
如:sed‘s/\/usr\/local\/bin/\/common\/bin/‘<old >new
等价于 sed‘s_/usr/local/bin_/common/bin_‘ <old >new
显然 , 此时用 "_" 作分割符比 "/" 好得多
如: sed ‘s/abc/(abc)/‘ <old >new
该例子还可以写成 sed ‘s/abc/(&)/‘ <old >new
sed ‘s/[a-z]*/(&)/‘ <old >new![]()
![]()
![]()

![]()
匹配操作符: value ~ /regexp/ 如果value匹配/regexp/,则返回真
value !~ /regexp/ 如果value不匹配/regexp/,则返回真
例如: awk ‘$2 > 10 {print"ok"}‘ input_file
awk ‘$3 ~ /^d/ {print"ok"}‘ input_file
awk ‘/^d/ || /x$/ {print"ok"}‘ input_file![]()
![]()
![]()
![]()
![]()
![]()
分类: 2014-06-24 11:27 1876人阅读 (0)
正则表达式只是一种表示法,只要工具支持这种表示法,那么该工具就可以处理正则表达式的字符串。vi grep ,awk ,sed 等都支持正则表达式.
1基础正则表达式
grep 工具,以前介绍过。
grep -[acinv] ‘搜索内容串‘ filename
-a 以文本文件方式搜索
-c 计算找到的符合行的次数
-i 忽略大小写
-n 顺便输出行号
-v 反向选择,即找 没有搜索字符串的行
其中搜索串可以是正则表达式!
1
搜索有the的行,并输出行号
$grep -n ‘the‘ regular_express.txt
搜索没有the的行,并输出行号
$grep -nv ‘the‘ regular_express.txt
2 利用[]搜索集合字符
[] 表示其中的某一个字符 ,例如[ade]
表示a或d或e
woody@xiaoc:~/tmp$ grep -n
‘t[ae]st‘ regular_express.txt
8:I can‘t finish the test.
9:Oh! the soup taste good!
可以用^符号做[]内的前缀,表示除[]内的字符之外的字符。
比如搜索oo前没有g的字符串所在的行. 使用 ‘[^g]oo‘ 作搜索字符串
woody@xiaoc:~/tmp$ grep -n ‘[^g]oo‘ regular_express.txt
2:apple is my favorite food.
3:Football game is not use feet only.
18:google is the best tools for search keyword.
19:goooooogle yes!
[] 内可以用范围表示,比如[a-z]
表示小写字母,[0-9] 表示0~9的数字, [A-Z] 则是大写字母们。[a-zA-Z0-9]表示所有数字与英文字符。 当然也可以配合^来排除字符。
搜索包含数字的行
woody@xiaoc:~/tmp$ grep -n ‘[0-9]‘ regular_express.txt
5:However ,this dress is about $ 3183 dollars.
15:You are the best is menu you are the no.1.
行首与行尾字符 ^ $. ^ 表示行的开头,$表示行的结尾( 不是字符,是位置)那么‘^$’ 就表示空行,因为只有
行首和行尾。
这里^与[]里面使用的^意义不同。它表示^后面的串是在行的开头。
比如搜索the在开头的行
woody@xiaoc:~/tmp$ grep -n ‘^the‘ regular_express.txt
12:the symbol ‘*‘ is represented as star.
搜索以小写字母开头的行
woody@xiaoc:~/tmp$ grep -n ‘^[a-z]‘ regular_express.txt
2:apple is my favorite food.
4:this dress doesn‘t fit me.
10:motorcycle is cheap than car.
12:the symbol ‘*‘ is represented as star.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let‘s go.
woody@xiaoc:~/tmp$
搜索开头不是英文字母的行
woody@xiaoc:~/tmp$ grep -n ‘^[^a-zA-Z]‘
regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
21:#I am VBird
woody@xiaoc:~/tmp$
$表示它前面的串是在行的结尾,比如 ‘\.‘
表示 . 在一行的结尾
搜索末尾是.的行
woody@xiaoc:~/tmp$ grep -n ‘\.$‘
regular_express.txt //.
是正则表达式的特殊符号,所以要用\转义
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn‘t fit me.
5:However ,this dress is about $ 3183 dollars.
6:GNU is free air not free beer.
.....
注意在MS的系统下生成的文本文件,换行会加上一个 ^M 字符。所以最后的字符会是隐藏的^M ,在处理Windows
下面的文本时要特别注意!
可以用cat dos_file | tr -d ‘\r‘ > unix_file 来删除^M符号。 ^M==\r
那么‘^$‘ 就表示只有行首行尾的空行拉!
搜索空行
woody@xiaoc:~/tmp$ grep -n ‘^$‘ regular_express.txt
22:
23:
woody@xiaoc:~/tmp$
搜索非空行
woody@xiaoc:~/tmp$ grep -vn ‘^$‘
regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
4:this dress doesn‘t fit me.
..........
任意一个字符. 与重复字符 *
在bash中*代表通配符,用来代表任意个字符,但是在正则表达式中,他含义不同,*表示有0个或多个 某个字符。
例如 oo*, 表示第一个o一定存在,第二个o可以有一个或多个,也可以没有,因此代表至少一个o.
点. 代表一个任意字符,必须存在。 g??d 可以用 ‘g..d‘ 表示。 good ,gxxd ,gabd .....都符合。
woody@xiaoc:~/tmp$ grep -n ‘g..d‘ regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
9:Oh! the soup taste good!
16:The world is the same with ‘glad‘.
woody@xiaoc:~/tmp$
搜索两个o以上的字符串
woody@xiaoc:~/tmp$ grep -n ‘ooo*‘ regular_express.txt //前两个o一定存在,第三个o可没有,也可有多个。
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! the soup taste good!
18:google is the best tools for search keyword.
19:goooooogle yes!
搜索g开头和结尾,中间是至少一个o的字符串,即gog, goog....gooog...等
woody@xiaoc:~/tmp$ grep -n
‘goo*g‘ regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
搜索g开头和结尾的字符串在的行
woody@xiaoc:~/tmp$ grep -n ‘g.*g‘ regular_express.txt // .*表示 0个或多个任意字符
1:"Open Source" is a good
mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let‘s go.
限定连续重复字符的范围 { }
. * 只能限制0个或多个, 如果要确切的限制字符重复数量,就用{范围} 。范围是数字用,隔开 2,5 表示2~5个,
2表示2个,2, 表示2到更多个
注意,由于{ }在SHELL中有特殊意义,因此作为正则表达式用的时候要用\转义一下。
搜索包含两个o的字符串的行。
woody@xiaoc:~/tmp$ grep -n ‘o\{2\}‘ regular_express.txt
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! the soup taste good!
18:google is the best tools for search keyword.
19:goooooogle yes!
搜索g后面跟2~5个o,后面再跟一个g的字符串的行。
woody@xiaoc:~/tmp$ grep -n
‘go\{2,5\}g‘ regular_express.txt
18:google is the best tools for search keyword.
搜索包含g后面跟2个以上o,后面再跟g的行。。
woody@xiaoc:~/tmp$ grep -n ‘go\{2,\}g‘ regular_express.txt
18:google is the best tools for search keyword.
19:goooooogle yes!
注意,相让[]中的^ - 不表现特殊意义,可以放在[]里面内容的后面。
‘[^a-z\.!^ -]‘ 表示没有小写字母,没有. 没有!, 没有空格,没有- 的 串,注意[]里面有个小空格。
另外shell 里面的反向选择为[!range], 正则里面是 [^range]
2扩展正则表达式
扩展正则表达式是对基础正则表达式添加了几个特殊构成的。
它令某些操作更加方便。
比如我们要去除 空白行和行首为 #的行, 会这样用:
woody@xiaoc:~/tmp$ grep -v ‘^$‘ regular_express.txt | grep -v ‘^#‘
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn‘t fit me.
............
然而使用支持扩展正则表达式的 egrep 与扩展特殊符号 | ,会方便许多。
注意grep只支持基础表达式, 而egrep 支持扩展的,其实 egrep 是 grep -E 的别名而已。因此grep -E 支持扩展正则。
那么:
woody@xiaoc:~/tmp$ egrep -v ‘^$|^#‘
regular_express.txt
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn‘t fit me.
....................
这里| 表示或的关系。 即满足 ^$ 或者 ^# 的字符串。
这里列出几个扩展特殊符号:
+,于 . * 作用类似,表示 一个或多个重复字符。
?, 于 . * 作用类似,表示0个或一个字符。
|,表示或关系,比如 ‘gd|good|dog‘ 表示有gd,good或dog的串
(),将部分内容合成一个单元组。比如 要搜索 glad 或 good 可以这样
‘g(la|oo)d‘
()的好处是可以对小组使用 + ? *
等。
比如要搜索A和C开头结尾,中间有至少一个(xyz) 的串,可以这样 :
‘A(xyz)+C‘
Grep : g (globally) search for a re (regular expression ) and p (print ) the results.
1、参数:
-I :忽略大小写
-c :打印匹配的行数
-l :从多个文件中查找包含匹配项
-v :查找不包含匹配项的行
-n:打印包含匹配项的行和行标
2、RE(正则表达式)
\ 忽略正则表达式中特殊字符的原有含义
^ 匹配正则表达式的开始行
$ 匹配正则表达式的结束行
\< 从匹配正则表达式的行开始
\>; 到匹配正则表达式的行结束
[ ] 单个字符;如[A] 即A符合要求
[ - ] 范围 ;如[A-Z]即A,B,C一直到Z都符合要求
. 所有的单个字符
* 所有字符,长度可以为0
3、举例
# ps -ef | grep in.telnetd
root 19955 181 0 13:43:53 ? 0:00 in.telnetd
# more size.txt size文件的内容
b124230
b034325
a081016
m7187998
m7282064
a022021
a061048
m9324822
b103303
a013386
b044525
m8987131
B081016
M45678
B103303
BADc2345
# more size.txt | grep ‘[a-b]‘ 范围 ;如[A-Z]即A,B,C一直到Z都符合要求
b124230
b034325
a081016
a022021
a061048
b103303
a013386
b044525
# more size.txt | grep ‘[a-b]‘*
b124230
b034325
a081016
m7187998
m7282064
a022021
a061048
m9324822
b103303
a013386
b044525
m8987131
B081016
M45678
B103303
BADc2345
# more size.txt | grep ‘‘ 单个字符;如[A] 即A符合要求
b124230
b034325
b103303
b044525
# more size.txt | grep ‘[bB]‘
b124230
b034325
b103303
b044525
B081016
B103303
BADc2345
# grep ‘root‘ /etc/group
root::0:root
bin::2:root,bin,daemon
sys::3:root,bin,sys,adm
adm::4:root,adm,daemon
uucp::5:root,uucp
mail::6:root
tty::7:root,tty,adm
lp::8:root,lp,adm
nuucp::9:root,nuucp
daemon::12:root,daemon
# grep ‘^root‘ /etc/group 匹配正则表达式的开始行
root::0:root
# grep ‘uucp‘ /etc/group
uucp::5:root,uucp
nuucp::9:root,nuucp
# grep ‘\<uucp‘ /etc/group
uucp::5:root,uucp
# grep ‘root$‘ /etc/group 匹配正则表达式的结束行
root::0:root
mail::6:root
# more size.txt | grep -i ‘b1..*3‘ -i :忽略大小写
b124230
b103303
B103303
# more size.txt | grep -iv ‘b1..*3‘ -v :查找不包含匹配项的行
b034325
a081016
m7187998
m7282064
a022021
a061048
m9324822
a013386
b044525
m8987131
B081016
M45678
BADc2345
# more size.txt | grep -in ‘b1..*3‘
1:b124230
9:b103303
15:B103303
# grep ‘$‘ /etc/init.d/nfs.server | wc -l
128
# grep ‘\$‘ /etc/init.d/nfs.server | wc –l 忽略正则表达式中特殊字符的原有含义
15
# grep ‘\$‘ /etc/init.d/nfs.server
case "$1" in
>;/tmp/sharetab.
echo "$path\t$res\t$fstype\t$opts\t$desc" \
>;>;/tmp/sharetab.
/usr/bin/touch -r /etc/dfs/sharetab /tmp/sharetab.
/usr/bin/mv−f/tmp/sharetab.
/etc/dfs/sharetab
if [ -f /etc/dfs/dfstab ] && /usr/bin/egrep -v ‘^[ ]*(#|$)‘ \
if [ $startnfsd -eq 0 -a -f /etc/rmmount.conf ] && \
if [ $startnfsd -ne 0 ]; then
elif [ ! -n "$_INIT_RUN_LEVEL" ]; then
while [ $wtime -gt 0 ]; do
wtime=`expr $wtime - 1`
if [ $wtime -eq 0 ]; then
echo "Usage: $0 { start | stop }"
# more size.txt
the test file
their are files
The end
# grep ‘the‘ size.txt
the test file
their are files
# grep ‘\<the‘ size.txt
the test file
their are files
# grep ‘the\>;‘ size.txt
the test file
# grep ‘\<the\>;‘ size.txt
the test file
# grep ‘\<[Tt]he\>;‘ size.txt
the test file
The end
1
grep [options] regex [files]
选项
含义
功能描述
-i
ignore case
忽略大小写
-v
invert match
不匹配匹配的
-l
file-with-match
输出匹配的文件名
-L
file-without-match
输出不匹配的文件名
-c
count
输出匹配的数目(行数)
-n
number
输出匹配行的同时在前面加上文件名及在文件名中的行数
-h
no-filename
抑制文件名的输出
符号
含义
举例
^
开始标记
"^abc"满足的例子abc、abcd
^
非(在[]内)
"[^abc]"满足的例子:ddd、mpd
$
结束标记
”abc$”满足的例子abc、mmabc
.
任意字符
"a.c"满足的例子abc、fapcc
\<
匹配单词开始
"\<abc"满足的例子abc、abcd
\>
匹配单词结束
"abc\>"满足的例子abc、pmrabc
|
或
"AAA|BBB"满足的例子AAA、BBBpp
符号
含义
举例
?
匹配前一个字符0或1次
"abc?"满足的例子ab、mabcd
*
匹配前一个字符≥0次
"abc*"满足的例子abbb、abcdk
+
匹配前一个字符≥1次
"abc+"满足的例子abcd、abcccdd
{}
{m}、{m,n}、{m,}、{,n}分别为匹配前一个字符m次、m到n次、≥m次、≤n次
"abc\{3,5\}"满足的例子abcccc、abcccccc
[]
[]内如果不是范围,选其一;是范围的话,范围内选其一
"m[abc]p"满足的例子acpd;m[1-9]p满足的例子m8pp
()
将候选的所有元素放在()内,用|隔开
"a(1|2|3)bc"满足的例子a1bc、mba3bcd
字符类
释义
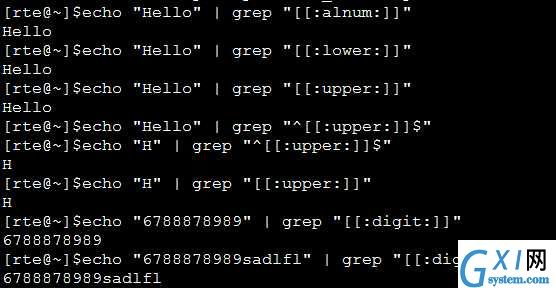
[:alnum:]
字母和数字,与[A-Za-z0-9]等价
[:word:]
[:alnum:]加上下划线_
[:alpa:]
字母,与[A-Za-z]等价
[:digit:]
数字,与[0-9]等价
[:xdigit:]
十六进制字符,与[0-9A-Fa-f等价]
[:blank:]
空格和制表符
[:graph:]
可见字符,靠扩33~126
[:lower:]
小写字母
[:upper:]
大写字母
[:print:]
可打印字符
[:space:]
空白字符,等价于[\t\r\n\v\f]
[:punct:]
标点符号
[:cntrl:]
ASCII控制码,包括字符0~31以及127
Shell正则表达式之grep、sed、awk实操笔记
投稿:junjie 字体:[增加 减小] 类型:转载 时间:2014-09-10
这篇文章主要介绍了Shell正则表达式之grep、sed、awk实操笔记,本文使用grep、sed、awk配合正则达到了一些需求和目的,需要的朋友可以参考下
# vi regular_express.txt
-------------------------------
"Open Source" is a good mechanism to develop programs.
apple is my favorite food.
Football game is not use feet only.
this dress doesn‘t fit me.
However, this dress is about $ 3183 dollars.
GNU is free air not free beer.
Her hair is very beauty.
I can‘t finish the test.
Oh! The soup taste good.
motorcycle is cheap than car.
This window is clear.
the symbol ‘*‘ is represented as start.
Oh!My god!
The gd software is a library for drafting programs.
You are the best is mean you are the no. 1.
The world <Happy> is the same with "glad".
I like dog.
google is the b



























